Memory-Augmented Neural Networks (MANNs): AI with Memory Power
Imagine a brilliant student who learns everything extremely fast but has one major problem: every morning, he forgets everything he learned the day before. For...

Imagine a brilliant student who learns everything extremely fast but has one major problem: every morning, he forgets everything he learned the day before. For...

When it comes to important decisions — such as determining the type of a tumor — the difference between relying on a single opinion and...

When teaching a child to recognize an apple, if they only see one red apple, they might assume that all apples must look exactly the...

Imagine you have an intelligent assistant that can answer any question, but when you ask about specific details of your company, internal protocols, or confidential...

Imagine your child sees a coffee cup for the first time. They can recognize that same cup from any angle - from above, from the...

Imagine asking an AI language model to write a formal email, but instead of professional text, you receive a completely irrelevant and sometimes even offensive...
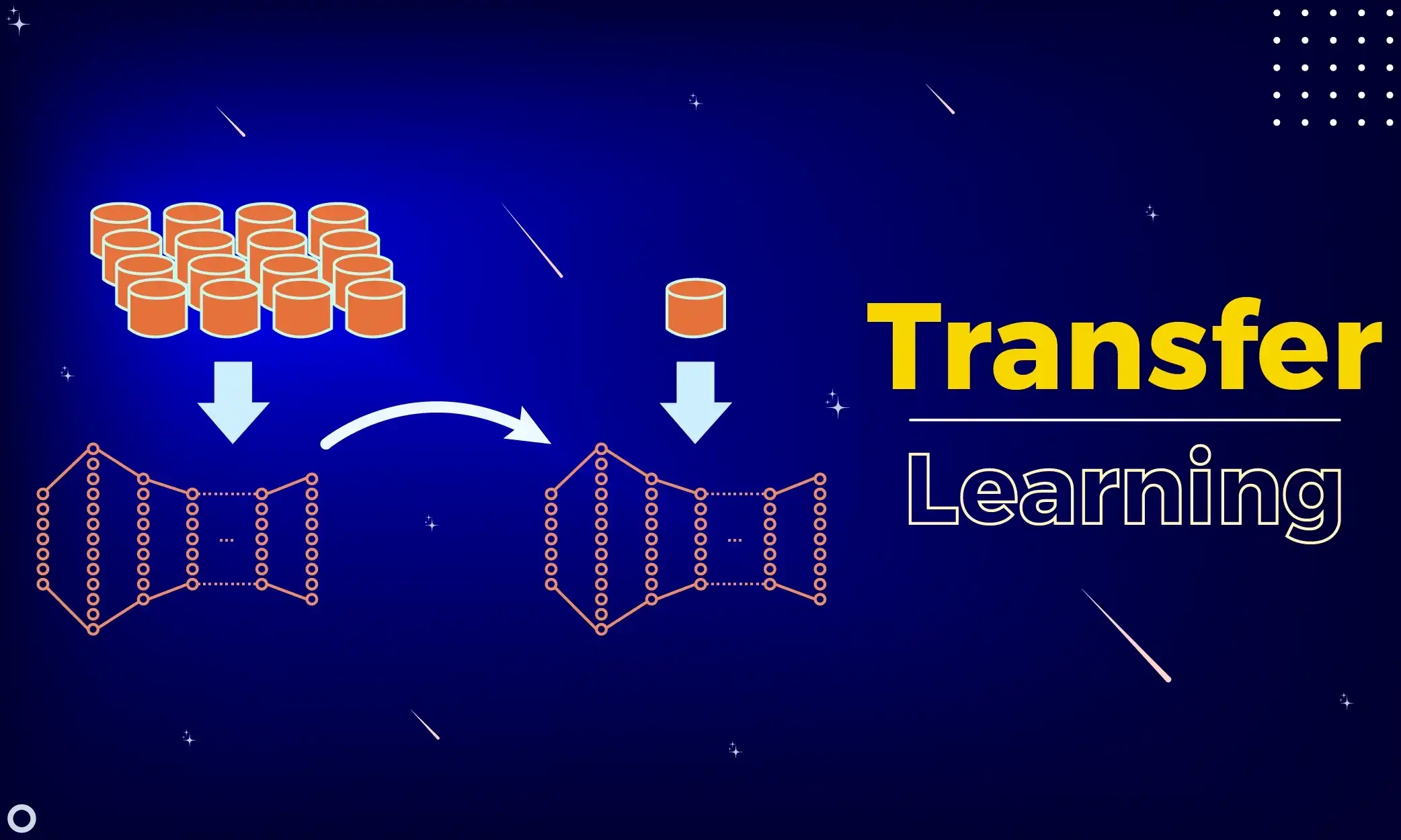
Imagine a heart specialist wanting to specialize in pulmonology. Should they forget all their medical knowledge and start from scratch? Absolutely not! They can leverage...

Imagine you've trained an AI model to recognize five different cat breeds. Now you want to add a sixth breed. In traditional machine learning, this...

Imagine you need to analyze a 1,000-page book. Would you really need to compare every word with every other word? Or could you focus only...

Imagine reading a complex book. Do you spend equal time and effort on every word? Certainly not! Some sentences are simple and you can quickly...

In the world of artificial intelligence, Transformer models have become the backbone of large language models. From GPT-4 to Claude and Gemini, all these models...

Imagine wanting to customize a 65-billion parameter language model for your specific business needs. In the not-so-distant past, this required access to multi-million dollar GPU...
Showing 13 to 24 of 90 articles