Blogs / AI Optimization and Efficiency: How to Make AI Models Faster and More Cost-Effective
AI Optimization and Efficiency: How to Make AI Models Faster and More Cost-Effective

Introduction
In an era where artificial intelligence is rapidly becoming the backbone of modern technologies, one major challenge remains: heavy computational costs and high energy consumption. Large language models like GPT-4 or Claude 4 require enormous resources for training and execution. For example, training an advanced language model can cost millions of dollars and consume energy equivalent to thousands of homes' annual consumption.
But why does this matter? Because without optimization, AI won't be accessible. Small companies can't benefit from this technology, end users face long delays, and the environment suffers from increased carbon emissions. AI optimization and efficiency isn't just a technical issue; it's the key to democratizing artificial intelligence and keeping it sustainable.
In this article, we'll deeply explore the methods, techniques, and challenges of AI optimization. From quantization techniques to novel architectures like Mixture of Experts (MoE) and Small Language Models (SLM), we'll examine all aspects under the microscope.
Efficiency Challenges in AI Models
1. Computational Costs and Energy
One of the biggest challenges of large AI models is the need for powerful Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs). These hardware components are not only expensive but also have very high energy consumption. For example, running a simple query with ChatGPT consumes approximately ten times more energy than a Google search.
Additionally, training large models like GPT-5 or Gemini 2.5 requires massive data centers with advanced cooling systems, which themselves bring significant costs.
2. Latency and User Experience
In the real world, users expect immediate responses from AI systems. But large models typically need considerable time for processing, especially when running on local devices. This delay can severely reduce user experience and limit the practical application of AI.
3. Hardware Limitations
Many users and companies don't have access to advanced hardware. Mobile devices, IoT systems, and even regular laptops can't easily run large models. This limitation doubles the need for optimization.
4. Scalability Issues
When the number of users of an AI system increases, execution costs grow linearly or even exponentially. Without proper optimization, serving millions of users will be impossible or extremely expensive.
Advanced AI Optimization Techniques
Quantization
Quantization is one of the most effective methods for reducing the size and increasing the speed of AI models. In this technique, model weights are converted from high-precision data types (like float32) to lower-precision types (like int8 or even int4).
Advantages:
- 75% reduction in model size using 8-bit quantization
- Significant increase in inference speed
- Reduced memory and energy consumption
Types of Quantization:
- Post-Training Quantization (PTQ): Quantization after model training
- Quantization-Aware Training (QAT): Training the model with quantization in mind from the start
- Dynamic Quantization: Dynamic quantization at runtime
For implementing quantization, you can use frameworks like TensorFlow and PyTorch which have built-in tools for this purpose.
Pruning
Pruning is the process of removing unnecessary neurons or connections from a neural network. Research has shown that many parameters in a deep model have negligible impact on final performance.
Types of Pruning:
- Unstructured Pruning: Removing individual weights
- Structured Pruning: Complete removal of neurons or layers
- Magnitude-based Pruning: Removing weights with small values
Using Pruning, you can remove up to 90% of a model's parameters while its accuracy only decreases by a few percent.
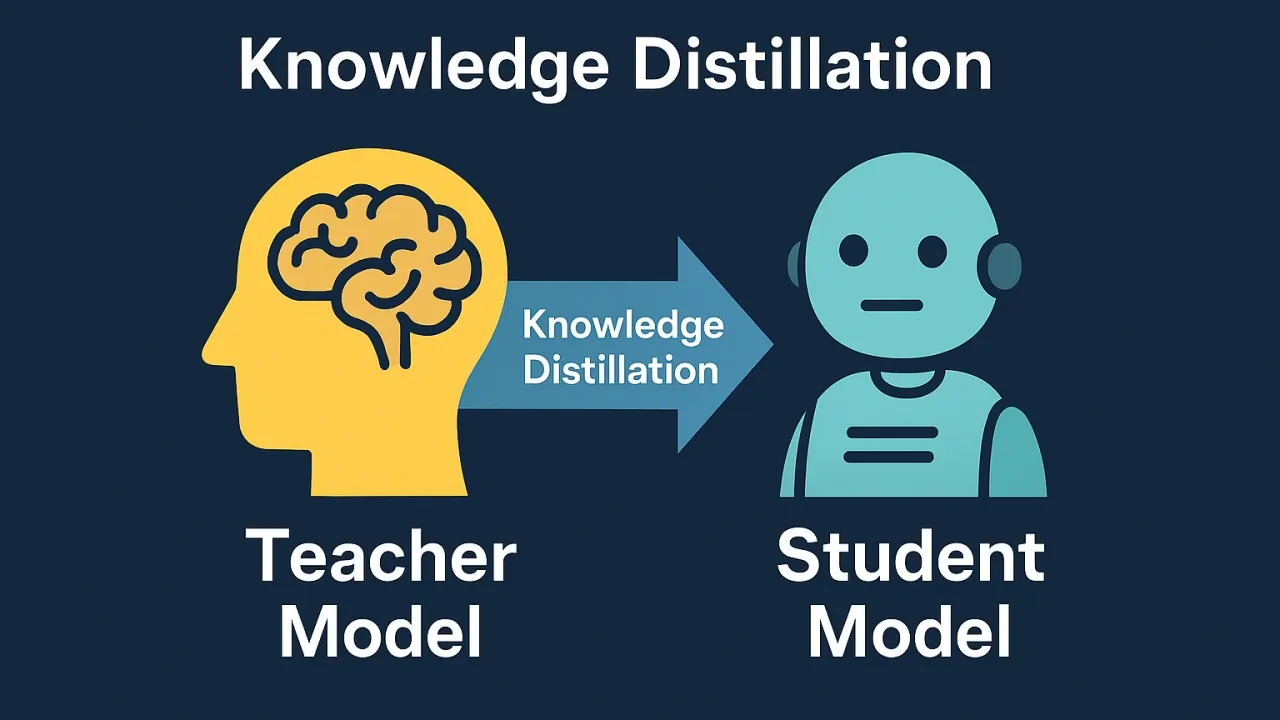
Knowledge Distillation
In this method, a smaller model (Student) learns from a larger model (Teacher). The student model tries to mimic the teacher model's behavior but with far fewer parameters.
This technique is very practical for building Small Language Models and allows you to create models that can run on local devices.
Low-Rank Adaptation (LoRA)
LoRA is a revolutionary technique for fine-tuning large models. Instead of updating all model weights, LoRA only adds and trains small matrices, which drastically reduces computational costs.
LoRA Advantages:
- 99% reduction in memory required for fine-tuning
- Ability to train on regular GPUs
- Preservation of original model quality
Edge AI and Local Processing
Edge AI refers to running AI models on local devices. This approach has many advantages:
- Elimination of the need for constant server communication
- Minimizing latency
- Preserving user privacy
- Reducing cloud infrastructure costs
For implementing Edge AI, you need extreme model optimization. Using frameworks like TensorFlow Lite or ONNX Runtime can be helpful.
Efficient Architectures for AI
Mixture of Experts (MoE)
MoE architecture is a clever method for increasing model capacity without proportionally increasing computational cost. In this architecture, only a portion of the model (typically 10-20%) is activated for each input.
How it works:
- The model consists of multiple "Experts"
- A Router network decides which experts are activated for each input
- Each expert specializes in a specific domain
Models like DeepSeek V3.2 use this architecture and deliver exceptional performance at low cost.
Optimized Transformers and Alternatives
The Transformer model, while powerful, has O(n²) computational complexity relative to input sequence length. Several more efficient alternatives include:
1. Mamba Architecture:
Mamba is built on State Space Models and has linear O(n) complexity. This architecture is much more efficient than Transformer for long sequences.
2. RWKV:
RWKV is a combination of RNN and Transformer that has the advantages of both: RNN's efficiency in inference and Transformer's power in training parallelization.
3. Liquid Neural Networks:
Liquid neural networks can dynamically adjust their parameters and are very suitable for changing environments.
Small Language Models (SLM)
Small language models have shown that bigger isn't always better. Models with less than a billion parameters can have exceptional performance for specific tasks.
Successful SLM examples:
- Phi-3 Mini from Microsoft with 3.8 billion parameters
- Gemma 2B from Google
- Expert models in specific domains
These models are ideal for building applications with AI on local devices.
Hardware-Level Optimization
Custom AI Chips
Custom AI chips are designed for specific artificial intelligence operations and have much higher efficiency than general-purpose CPUs or even GPUs.
Types of Custom Chips:
- TPU (Tensor Processing Unit): Designed by Google for matrix operations
- NPU (Neural Processing Unit): Available in modern smartphones
- IPU (Intelligence Processing Unit): Built by Graphcore
- Apple Neural Engine: In M and A series chips
Neuromorphic Computing
Neuromorphic computing attempts to mimic brain structure. These chips use event-driven processing and have much lower energy consumption.
Neuromorphic chips like Intel Loihi 2 can perform AI tasks with a fraction of the energy required by traditional GPUs.
Quantum AI
Quantum artificial intelligence is still in its early stages but has the potential to completely change the game. Quantum computers can solve certain optimization problems exponentially faster than classical computers.
Software Optimization Techniques
Efficient Attention Mechanisms
The Attention mechanism in Transformers is the main performance bottleneck. Several optimized versions exist:
1. Flash Attention:
Optimal use of GPU memory to reduce Attention computation time
2. Multi-Query Attention (MQA):
Reusing Key and Value to reduce memory
3. Grouped-Query Attention (GQA):
Middle ground between MQA and standard Multi-Head Attention
4. Sparse Attention:
Computing Attention only for a portion of tokens, as used in DeepSeek V3.2
Caching and Optimization in Inference
KV Caching:
Storing computed Key-Values for previous tokens to avoid recomputation. This technique can increase text generation speed by 2-3 times.
Speculative Decoding:
Using a small model to predict next tokens and then verifying them with the large model
Batching:
Processing multiple requests simultaneously for optimal GPU utilization
Memory and Storage Solutions
Gradient Checkpointing:
Storing only a portion of activations during training and recomputing the rest when needed
Mixed Precision Training:
Using float16 or bfloat16 instead of float32 in most computations
Activation Checkpointing:
Reducing memory usage by trading between time and memory
Retrieval-Augmented Generation (RAG) for Efficiency
RAG allows language models to use an external knowledge base instead of storing all knowledge in parameters. This approach has many advantages:
- Reduced need for many parameters
- Ability to update knowledge without retraining
- Reduction in Hallucination
- Increased response reliability
RAG is particularly suitable for applications requiring domain-specific knowledge (such as medical or legal).
Federated Learning for Privacy and Efficiency
Federated learning enables training AI models on distributed data without moving the data. This approach:
- Preserves privacy
- Reduces data transfer costs
- Enables use of sensitive data
- Is ideal for learning from edge devices
Optimization Strategies for Specific Applications
Optimization for Image and Video Generation
Image generation and video models require tremendous computational resources. Optimization solutions include:
1. Latent Diffusion Models:
Performing Diffusion in latent space instead of pixel space
2. Few-Step Generation:
Reducing diffusion steps from 50-100 to 4-8 steps
3. Model Distillation:
Using smaller models trained from large models
Optimization for Natural Language Processing
NLP is one of the most expensive AI domains. Optimization techniques:
- Using efficient Tokenization
- Fine-tuning with LoRA instead of Full Fine-tuning
- Using Prompt Engineering to improve results without training
Optimization for Real-Time Systems
Applications like autonomous vehicles and robotics need real-time responses:
- Using small, specialized models
- Implementation on Edge with custom hardware
- Using hierarchical models (first fast model, then more accurate model if needed)
Future Challenges and Solutions
Self-Improving AI Models
Self-improving models can optimize themselves. This approach is promising but has challenges:
- Risk of over-optimizing for wrong metrics
- Need for careful monitoring to prevent unwanted behaviors
- Balance between improvement and stability
Multi-Agent Systems and Distributed Optimization
Multi-agent systems can divide complex tasks into subtasks, with each agent focusing on a specific part. This approach enables local optimization and better efficiency.
World Models and Efficient Learning
World Models allow AI to have mental simulations of the world. This can reduce the need for actual training data and make learning more efficient.
Practical Tools and Frameworks
Optimization Frameworks
1. ONNX Runtime:
Optimized execution of machine learning models on different hardware
2. TensorRT:
NVIDIA's optimization library for fast inference
3. OpenVINO:
Intel's tool for model optimization and deployment
4. Hugging Face Optimum:
Optimization tools for Transformer models
Optimized Cloud AI Platforms
Google Cloud AI and other cloud providers offer automatic optimization services:
- Auto-scaling for load management
- Model optimization APIs
- Custom hardware (TPU, GPU)
Performance Measurement Metrics
To evaluate optimization, you must consider various metrics:
1. Throughput:
Number of requests processed per time unit
2. Latency:
Response time for a single request
3. Memory Usage:
RAM and VRAM consumption
4. Energy Consumption:
Energy consumption per inference
5. Model Size:
Model size on disk
6. Accuracy:
Model accuracy compared to unoptimized version
Case Studies and Successes
DeepSeek: Low-Cost Optimization
DeepSeek showed that GPT-4 level models can be built with limited budget. Their strategies included:
- Using MoE architecture
- Extreme optimization of training code
- Using cheaper hardware with smart management
Claude and High Efficiency
Claude and its newer versions like Claude Sonnet 4.5 have shown that you can be both intelligent and efficient. Using advanced optimization techniques has given these models exceptional response speed.
O3 Mini and O4 Mini: Small-Scale Efficiency
O3 Mini and O4 Mini from OpenAI are excellent examples of optimized models that deliver acceptable performance with fewer resources.
Cost Reduction Strategies in Production
Using Model Cascading
Instead of using one large model for all requests, you can use a hierarchical system:
- The request first goes to a small, fast model
- If confidence is low, it's transferred to a medium model
- Only complex requests go to the large model
This approach can reduce costs by up to 70%.
Prompt Caching
Caching repetitive parts of prompts can significantly reduce costs. This technique is especially useful for chat with AI that has long context.
Batch Processing
Batch processing requests instead of processing them individually can increase efficiency by up to 10 times. This approach is ideal for applications that don't need immediate responses.
Optimization for Specialized Applications
AI in Medicine and Disease Diagnosis
AI in diagnosis and treatment needs high accuracy but must also be fast. Solutions:
- Using specialized models trained on medical data
- Optimization for hardware available in hospitals
- Using Edge AI to preserve patient privacy
AI in Cybersecurity
Artificial intelligence in cybersecurity needs real-time processing:
- Lightweight models for anomaly detection
- Using Isolation Forest for anomaly detection
- Distributed architectures for scalability
AI in Finance and Trading
AI in trading needs very low latency:
- Using simpler models for fast decision-making
- Data preprocessing to reduce real-time load
- Using optimized predictive models
Ethical and Environmental Considerations
Reducing Carbon Footprint
AI optimization isn't just an economic issue but an ethical and environmental one. Ethics in artificial intelligence requires that we:
- Use renewable energy for training
- Train models only when truly necessary
- Reuse pre-trained models
Fair Access to AI
Optimization makes AI accessible to everyone, not just large companies. This is critical for the future of artificial intelligence and its democratization.
Practical Guide to Start Optimization
Step 1: Profile the Model
First, you need to understand where your model has bottlenecks:
- Using profiling tools like PyTorch Profiler
- Identifying layers that take more time
- Reviewing memory usage
Step 2: Choose Appropriate Technique
Based on your needs, choose one or a combination of the following techniques:
- For size reduction: Quantization and Pruning
- For latency reduction: Knowledge Distillation and Model Caching
- For training cost reduction: LoRA and Federated Learning
Step 3: Implementation and Testing
- Start with one technique and evaluate results
- Compare key metrics (accuracy, speed, memory)
- Fine-tune parameters for further optimization
Step 4: Monitoring and Continuous Improvement
- Use monitoring tools to track performance
- A/B testing to compare different versions
- Regular updates with new techniques
Development Tools and Libraries
TensorFlow and PyTorch
TensorFlow and PyTorch both have comprehensive optimization tools:
TensorFlow:
- TensorFlow Lite for mobile
- TensorFlow.js for browser
- TensorFlow Serving for production
PyTorch:
- TorchScript for optimization
- PyTorch Mobile
- TorchServe for deployment
Specialized Libraries
- Keras: High-level interface for rapid building
- NumPy: Efficient numerical computing
- OpenCV: Image processing optimization
The Future of AI Optimization
AI Agents and Automatic Optimization
AI Agents can decide themselves when and how to optimize. Agentic AI is the future of optimization.
AGI and Ultimate Efficiency
The path toward AGI requires fundamental advances in efficiency. We can't build AGI unless we can run it with reasonable resources.
Physical AI and Robotics
Physical AI needs more extreme optimization since it must run on robots with limited resources.
Conclusion
AI optimization and efficiency isn't a choice but a necessity. In a world where AI is rapidly expanding, only organizations and developers who can make their models efficient, fast, and cost-effective will succeed.
From simple quantization to advanced architectures like MoE, we have many tools and techniques available. The key to success is deep understanding of project-specific needs and choosing the right combination of these techniques.
Remember that optimization is a continuous process. With rapid technological advancement, new methods are constantly being introduced. Only through continuous learning and testing new techniques can you remain a leader in this field.
The future of AI belongs to those who can combine power and efficiency. Using the solutions presented in this article, you too can be part of this future and take your AI models to a new level of performance.