Blogs / Small Language Models (SLM): The Efficiency Revolution in Artificial Intelligence
Small Language Models (SLM): The Efficiency Revolution in Artificial Intelligence

Introduction
In the world of artificial intelligence, which has always moved toward larger and more powerful models, we are now witnessing a different transformation. Small Language Models (SLMs) have emerged as efficient, cost-effective, and practical alternatives to large language models. These models prove that bigger is not always better, and in many applications, smaller models can outperform their larger counterparts.
With the growing need for local processing, cost reduction, and enhanced privacy, SLMs have captured the attention of organizations, developers, and researchers. With fewer than 10 billion parameters, these models can run on edge devices such as smartphones, security cameras, and IoT sensors, delivering AI services without requiring constant internet connectivity.
In this article, we dive deep into small language models, exploring their advantages, architectures, applications, and the future of this technology.
What Are Small Language Models?
Small Language Models are optimized, lightweight versions of large language models designed to operate in resource-constrained environments. Unlike large language models (LLMs) like GPT-4, which have hundreds of billions of parameters and require powerful servers, SLMs typically have a few million to a few billion parameters.
The exact definition of an SLM varies based on parameter count, but generally, models with fewer than 10 billion parameters fall into this category. These models are built using advanced techniques such as Distillation, Quantization, and Pruning to maintain acceptable performance while running on devices with limited resources.
Differences Between SLMs and LLMs
The primary differences between SLMs and LLMs lie in size, cost, and execution environment:
- Size: LLMs have 10 billion parameters or more, while SLMs typically have fewer than 10 billion parameters.
- Cost: Training GPT-4 is estimated to cost millions of dollars, whereas SLMs can be trained on more limited budgets.
- Execution Environment: LLMs require powerful cloud servers, but SLMs can run on local devices.
- Energy Consumption: SLMs consume significantly less energy, making them more suitable for mobile and IoT devices.
SLM Architecture and Building Techniques
Building small language models is a complex process that leverages various techniques:
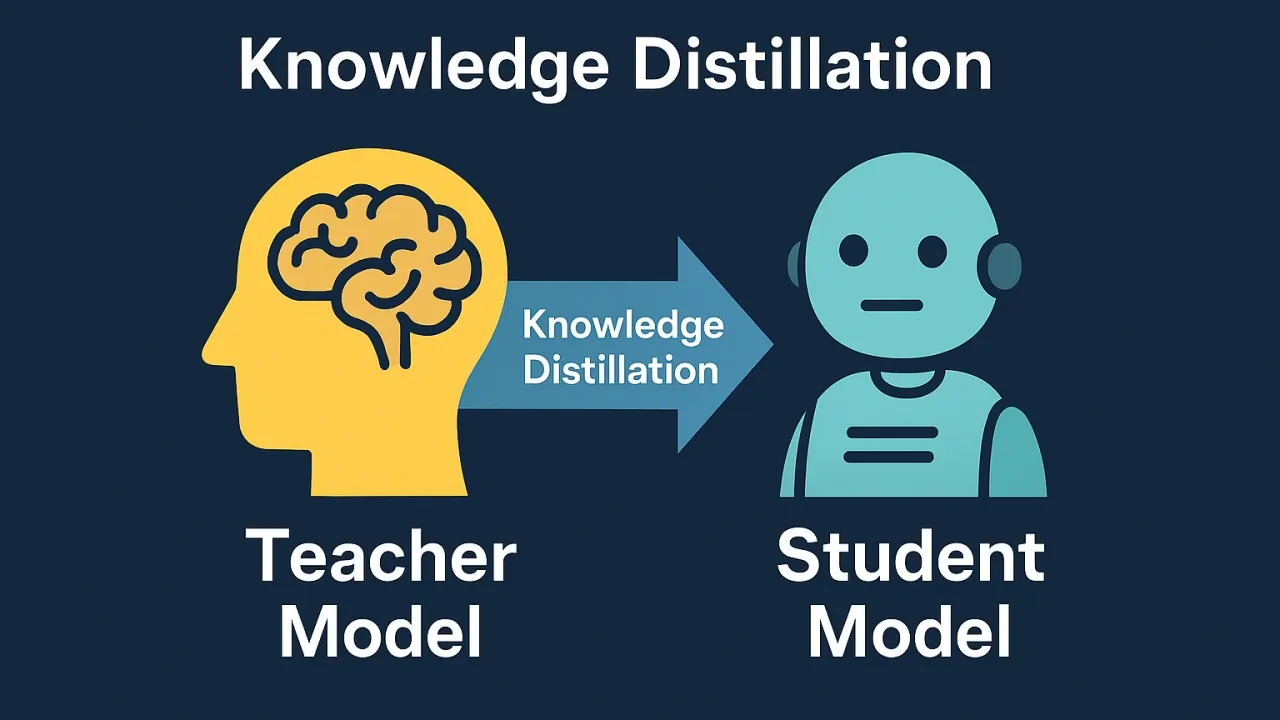
Knowledge Distillation
In this method, a smaller model (student) learns from a larger model (teacher). The small model attempts to mimic the behavior and knowledge of the large model but with significantly fewer parameters. This technique allows the small model to retain much of the larger model's performance.
Quantization
Quantization reduces the precision of numbers in the model. Instead of using 32-bit numbers, 8-bit or even 4-bit numbers are used, significantly reducing the model size and increasing inference speed.
Pruning
This technique removes less important connections and neurons from the network. Pruning can be structured (removing entire layers or filters) or unstructured (removing individual parameters).
Efficient Architectures
Using more efficient architectures, such as optimized Transformers, lighter attention mechanisms, and smaller layers, helps reduce model size.
Advantages of Small Language Models
Reduced Operational Costs
One of the biggest advantages of SLMs is their significantly lower costs. Training, deploying, and running these models are far less expensive than LLMs. Organizations can leverage AI capabilities without heavy investments in cloud infrastructure.
Local Processing and Privacy
SLMs can run on local devices, eliminating the need to send data to cloud servers. This is critical for industries handling sensitive data, such as healthcare and finance.
Speed and Low Latency
By running locally, SLMs eliminate network latency and provide instant responses. This is essential for real-time applications like robotics and autonomous systems.
Energy Efficiency
SLMs consume far less energy, making them ideal for battery-powered devices like smartphones, tablets, and IoT devices. This energy efficiency also contributes to reducing carbon footprints and promoting environmental sustainability.
Specialization for Specific Tasks
SLMs can be fine-tuned for specific tasks, often outperforming general-purpose LLMs in those tasks. This specialization leads to higher accuracy and more efficient resource use.
Independence from Internet Connectivity
Local execution means no reliance on constant internet connectivity, which is highly beneficial for regions with limited internet access or environments with unstable connections.
Popular Small Language Models
Llama 3.2
Meta’s Llama 3.2, with 1B and 3B versions, offers small and efficient models designed for on-device execution, performing well in various NLP tasks.
Gemma 3
Google’s Gemma 3 models include text-only and multimodal versions, excelling in text, image, and audio processing for diverse applications.
Microsoft Phi-3.5
Microsoft’s Phi-3 family, with 3B and 14B models, supports long contexts (128K tokens) and performs exceptionally well in logical and mathematical tasks, suitable for document summarization and complex question-answering.
Mistral NeMo
Mistral NeMo, a 12B model developed in collaboration with Mistral AI and NVIDIA, offers a good balance between size and performance, making it suitable for commercial applications.
Qwen 2.5
Alibaba’s Qwen 2.5 models, trained on a massive dataset (18 trillion tokens), offer strong multilingual support and handle up to 128K tokens of context.
DeepSeek-R1
DeepSeek is an advanced NLP model with smaller versions that deliver impressive performance in natural language processing tasks.
Applications of Small Language Models
Edge Computing and IoT
One of the most significant applications of SLMs is in edge computing and Internet of Things (IoT). These models can run on sensors, security cameras, wearable devices, and smart home appliances, enabling local decision-making.
Mobile Devices
Smartphones and tablets can use SLMs for voice assistants, real-time translation, text recognition, and other AI capabilities, enhancing user experience and privacy.
Autonomous Vehicles
In the automotive industry, SLMs are used for fast, local decision-making in ADAS and autonomous vehicles, where low latency and local processing are critical.
Security Systems
Face recognition, suspicious behavior detection, and real-time video analysis in cybersecurity and physical security systems benefit from SLMs.
Healthcare
In healthcare, SLMs are used for disease diagnosis, medical image analysis, and treatment recommendations. Local processing ensures patient privacy, a critical requirement in this sector.
Small and Medium Businesses
Small businesses with limited budgets can leverage SLMs for customer service, digital marketing, content creation, and data analysis.
Education
In the education sector, SLMs are used for teaching assistants, automated grading, content translation, and personalized learning experiences.
Smart Agriculture
In smart agriculture, SLMs are used for plant health analysis, yield prediction, and water resource management.
SLMs and Agentic AI Systems
Recent research shows that SLMs are highly suitable for Agentic AI systems. These systems involve multiple agents collaborating to perform complex tasks. Using LLMs for all components is highly costly.
SLMs can handle specific tasks like classification, local decision-making, and function calling, while LLMs are reserved for more complex tasks requiring deep reasoning. This combination reduces costs, increases speed, and improves scalability.
Federated Learning and SLMs
One innovative approach to improving SLMs is Federated Learning. In this method, small models are trained on various devices, and only model updates (not raw data) are sent to a central server.
This approach preserves privacy, reduces network bandwidth, and leverages local device data to improve the model. Combining Federated Learning with SLMs offers a powerful solution for organizations looking to utilize distributed data without compromising privacy.
Challenges of Small Language Models
Knowledge Limitations
Due to their smaller size, SLMs have less knowledge and information compared to LLMs. They may perform less effectively in complex or multi-domain tasks.
Need for Specialization
For optimal performance, SLMs often require fine-tuning for specific tasks, which demands data, time, and expertise.
Hallucination
Hallucination in language models remains a challenge. SLMs may generate incorrect or nonsensical information, which must be managed using various techniques.
Context Limitations
Many SLMs lack support for long contexts, limiting their use in certain applications.
Hardware Optimization Needs
Efficient execution of SLMs on edge devices requires specific hardware optimizations, such as AI accelerators like NPUs, TPUs, or specialized GPUs.
The Future of Small Language Models
The future of SLMs is very promising. With advancements in compression techniques, more efficient architectures, and optimized hardware, these models are expected to deliver better performance and become integrated into more devices.
Integration with Multimodal AI
Multimodal models that can process text, images, audio, and video are gradually becoming available in smaller versions.
Increased Use in Smart Cities
Smart cities will increasingly use SLMs for traffic management, energy, security, and public services.
Integration with Quantum Computing
Combining SLMs with quantum computing could elevate performance and efficiency to new levels.
Standardization and Better Tools
The development of standards and better tools for training, deploying, and maintaining SLMs will accelerate their adoption.
New Architectures
Novel architectures like Mamba and Mixture of Experts (MoE) will help smaller models achieve better performance with limited resources.
Increased Accessibility
With reduced costs and hardware requirements, SLMs make AI more accessible to small organizations, developing countries, and individual developers.
SLM vs. LLM: Which to Choose?
Choosing between SLM and LLM depends on the specific needs of your project:
Choose SLM if:
- You need local processing and high privacy.
- You have limited computational resources and budget.
- Low latency is critical.
- You want to run on mobile or edge devices.
- Your task is specialized and limited in scope.
Choose LLM if:
- You need extensive knowledge and complex reasoning.
- Your tasks are diverse and multi-domain.
- Output quality is more important than cost.
- You have access to robust cloud infrastructure.
- You require very long context windows.
In many cases, combining SLMs and LLMs offers the best solution, using SLMs for simple, fast tasks and LLMs for complex tasks to achieve an optimal balance of performance and cost.
Tools and Frameworks for SLM Development
Several tools and frameworks are available for working with SLMs:
Ollama
Ollama is a popular tool for running language models locally, supporting models like Llama, Mistral, Phi, and Gemma, making them easy to use.
TensorFlow Lite
TensorFlow Lite is a lightweight version of TensorFlow for mobile and edge devices, offering optimizations for efficient model execution.
PyTorch Mobile
PyTorch Mobile enables running PyTorch models on iOS and Android devices.
ONNX Runtime
ONNX Runtime is a cross-platform inference engine that provides optimized performance for running various models and is compatible with diverse hardware.
Hugging Face Transformers
The Transformers library from Hugging Face provides easy access to hundreds of models, including popular SLMs, and offers powerful tools for fine-tuning and deployment.
LangChain
LangChain is a popular framework for developing applications based on LLMs and SLMs, simplifying the creation of AI agents.
Key Tips for Effective SLM Use
Choosing the Right Model
Before selecting an SLM, carefully evaluate your needs:
- What type of task needs to be performed?
- What level of accuracy is required?
- What are the hardware constraints?
- Do you need multilingual support?
- How much training data is available?
Fine-tuning and Adaptation
For optimal performance, SLMs should be fine-tuned for your specific task. Modern techniques like LoRA (Low-Rank Adaptation) and QLoRA enable fine-tuning with limited resources.
Optimization and Quantization
Post-training optimization is essential for efficient deployment. Quantization to 8-bit or 4-bit can reduce model size by up to 75% without significant accuracy loss.
Context Management
Given the context limitations of SLMs, techniques like Retrieval-Augmented Generation (RAG) can help models access more information.
Monitoring and Evaluation
Continuous monitoring of model performance and identifying hallucination or errors is critical. Using appropriate metrics and regular testing ensures output quality.
SLMs and AI Democratization
One of the most significant impacts of SLMs is democratizing access to AI. Before their emergence, only large companies with million-dollar budgets could leverage the power of language models. Now:
- Startups and small businesses can create AI solutions with limited budgets.
- Researchers and universities can conduct advanced research without expensive infrastructure.
- Developing countries can develop AI technologies without reliance on foreign cloud services.
- Individual developers can create innovative applications.
This democratization fosters innovation, competition, and the development of solutions tailored to local needs.
SLMs and Environmental Sustainability
Another key advantage of SLMs is their positive environmental impact. Training and running large LLMs consume vast amounts of energy, resulting in significant carbon footprints. SLMs, with their lower energy consumption:
- Reduced carbon emissions: Lower energy consumption means fewer greenhouse gas emissions.
- Optimized resource use: Less need for large data centers and servers.
- Extended device lifespan: Efficient execution on older hardware reduces the need for upgrades.
- Reduced bandwidth: Local processing eliminates the need to send data to servers.
These features make SLMs a more sustainable and responsible choice for organizations aiming to reduce their environmental impact.
Case Studies and Real-World Successes
SLMs in Healthcare
Hospitals using SLMs for medical image analysis have increased diagnosis speed by up to 60% while preserving patient privacy.
Smart Vehicles
Automotive manufacturers use SLMs for voice assistants and ADAS systems that operate without internet connectivity, achieving latency under 50 milliseconds.
Precision Agriculture
Farmers using SLMs on drones and farm sensors can analyze plant health and reduce water consumption by up to 40%.
Retail and Commerce
Retail stores use SLMs for customer behavior analysis, inventory management, and personalized recommendations, leading to a 25% increase in sales.
Emerging Trends in SLMs
On-Device Training
A new trend is enabling model training directly on devices, allowing models to learn from user behavior and preferences without sending data to servers.
Hybrid Models
Hybrid combinations of SLMs and LLMs, where SLMs handle simple tasks locally and queries are sent to LLMs in the cloud when needed.
Specialized Accelerators
The development of specialized AI processors like Apple Neural Engine, Google TPU, and Qualcomm Hexagon makes SLM execution highly efficient.
Cross-Platform Compatibility
New tools and standards enable running SLMs across platforms (iOS, Android, Windows, Linux) without significant modifications.
How to Get Started with SLMs?
To start working with small language models, follow these steps:
Step 1: Identify Needs
Define the task or problem you want to solve. Do you need text processing, classification, summarization, or question-answering?
Step 2: Choose a Model
Select an appropriate SLM based on your needs. Models like Phi-3.5, Llama 3.2, or Gemma 2 are great starting points.
Step 3: Test and Evaluate
Test the model with your data and evaluate its performance. Fine-tune if necessary.
Step 4: Optimize
Optimize the model for deployment using techniques like Quantization and Pruning.
Step 5: Deploy
Deploy the model on the target device or server and begin monitoring its performance.
Step 6: Continuous Improvement
Continuously improve the model based on user feedback and performance metrics.
Conclusion
Small Language Models have shown that AI doesn’t need massive models to be effective. By combining efficiency, low cost, high privacy, and local execution, SLMs are reshaping the AI landscape.
These models offer numerous benefits not only for businesses and organizations but also for society. Democratizing AI access, reducing environmental impact, and enabling broader innovation are among the key achievements of SLMs.
With ongoing advancements in architectures, compression techniques, and specialized hardware, the future of SLMs is highly promising. Organizations and developers adopting this technology now will gain a significant competitive advantage in the future.
Final Recommendation: If you’re looking for a smart, cost-effective, and privacy-preserving solution for your AI needs, be sure to explore SLMs. They may be exactly what your project requires.