وبلاگ / مدلهای زبانی کوچک (Small Language Models): انقلاب کارآمدی در هوش مصنوعی
مدلهای زبانی کوچک (Small Language Models): انقلاب کارآمدی در هوش مصنوعی

مقدمه
در دنیای هوش مصنوعی که همواره به سمت مدلهای بزرگتر و قدرتمندتر حرکت میکرد، اکنون شاهد تحولی متفاوت هستیم. مدلهای زبانی کوچک (Small Language Models) یا SLMها به عنوان جایگزینی کارآمد، اقتصادی و عملی برای مدلهای زبانی بزرگ ظهور کردهاند. این مدلها ثابت میکنند که همیشه بزرگتر بودن به معنای بهتر بودن نیست و در بسیاری از کاربردها، مدلهای کوچکتر میتوانند عملکرد بهتری داشته باشند.
با رشد روزافزون نیاز به پردازش محلی، کاهش هزینهها و افزایش حریم خصوصی، SLMها توجه سازمانها، توسعهدهندگان و محققان را به خود جلب کردهاند. این مدلها با پارامترهای کمتر از 10 میلیارد، قادرند در دستگاههای لبه (Edge Devices) مانند گوشیهای هوشمند، دوربینهای امنیتی و سنسورهای IoT اجرا شوند و خدمات هوش مصنوعی را بدون نیاز به اتصال دائمی به اینترنت ارائه دهند.
در این مقاله به بررسی عمیق مدلهای زبانی کوچک، مزایای آنها، معماریها، کاربردها و آینده این فناوری میپردازیم.
مدلهای زبانی کوچک چیست؟
مدلهای زبانی کوچک نسخههای بهینهشده و سبکتر از مدلهای زبانی بزرگ هستند که برای اجرا در محیطهای محدود از نظر منابع طراحی شدهاند. برخلاف مدلهای زبانی بزرگ (LLM) مانند GPT-4 که دارای صدها میلیارد پارامتر هستند و نیازمند سرورهای قدرتمند میباشند، SLMها معمولاً دارای چند میلیون تا چند میلیارد پارامتر هستند.
تعریف دقیق SLM بر اساس تعداد پارامترها متفاوت است، اما به طور کلی مدلهایی با کمتر از 10 میلیارد پارامتر در این دسته قرار میگیرند. این مدلها با استفاده از تکنیکهای پیشرفته مانند Distillation، Quantization و Pruning ساخته میشوند تا بتوانند با حفظ کیفیت قابل قبول، در دستگاههای با منابع محدود اجرا شوند.
تفاوت SLM و LLM
تفاوت اصلی بین SLM و LLM در اندازه، هزینه و محل اجرا است:
- اندازه: LLMها دارای 10 میلیارد پارامتر یا بیشتر هستند، در حالی که SLMها معمولاً کمتر از 10 میلیارد پارامتر دارند.
- هزینه: هزینه آموزش GPT-4 میلیونها دلار تخمین زده میشود، در حالی که SLMها با بودجههای محدودتر قابل آموزش هستند.
- محل اجرا: LLMها نیازمند سرورهای ابری قدرتمند هستند، اما SLMها میتوانند روی دستگاههای محلی اجرا شوند.
- مصرف انرژی: SLMها مصرف انرژی بسیار کمتری دارند و برای دستگاههای موبایل و IoT مناسبتر هستند.
معماری و تکنیکهای ساخت SLM
ساخت مدلهای زبانی کوچک یک فرآیند پیچیده است که از تکنیکهای مختلفی استفاده میکند:
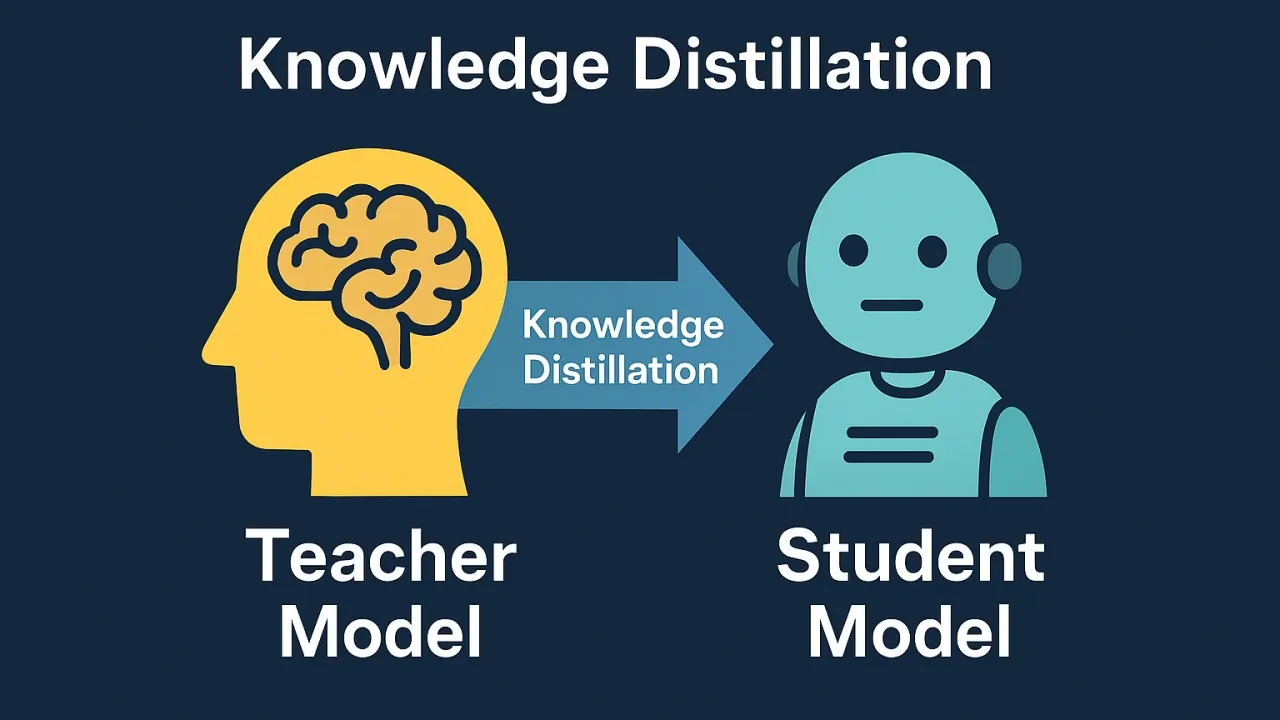
Knowledge Distillation
در این روش، یک مدل کوچک (Student) از یک مدل بزرگ (Teacher) یاد میگیرد. مدل کوچک سعی میکند رفتار و دانش مدل بزرگ را تقلید کند، اما با تعداد پارامترهای بسیار کمتر. این تکنیک به مدل کوچک اجازه میدهد تا بخش قابل توجهی از عملکرد مدل بزرگ را حفظ کند.
Quantization
کوانتیزیشن فرآیند کاهش دقت اعداد در مدل است. به جای استفاده از اعداد 32-bit، از اعداد 8-bit یا حتی 4-bit استفاده میشود. این کار حجم مدل را به طور قابل توجهی کاهش میدهد و سرعت استنتاج را افزایش میدهد.
Pruning
در این تکنیک، اتصالات و نورونهای کماهمیت در شبکه حذف میشوند. Pruning میتواند structured (حذف کامل لایهها یا فیلترها) یا unstructured (حذف پارامترهای منفرد) باشد.
Efficient Architectures
استفاده از معماریهای کارآمدتر مانند Transformer بهینهشده، attention mechanisms سبکتر و لایههای کوچکتر به کاهش اندازه مدل کمک میکند.
مزایای مدلهای زبانی کوچک
کاهش هزینههای عملیاتی
یکی از بزرگترین مزایای SLMها، کاهش چشمگیر هزینهها است. هزینههای آموزش، استقرار و اجرای این مدلها به مراتب کمتر از LLMهاست. سازمانها میتوانند بدون نیاز به سرمایهگذاری سنگین در زیرساختهای ابری، از قابلیتهای هوش مصنوعی بهرهمند شوند.
پردازش محلی و حریم خصوصی
SLMها میتوانند روی دستگاههای محلی اجرا شوند، بنابراین نیازی به ارسال دادهها به سرورهای ابری نیست. این ویژگی برای صنایعی که با اطلاعات حساس سروکار دارند مانند بهداشت و درمان و مالی بسیار حیاتی است.
سرعت و تأخیر کم
با اجرا در دستگاه محلی، SLMها تأخیر شبکه را حذف میکنند و پاسخهای فوری ارائه میدهند. این ویژگی برای کاربردهای real-time مانند رباتها و سیستمهای خودکار ضروری است.
کارایی انرژی
SLMها مصرف انرژی بسیار کمتری دارند، که این امر آنها را برای دستگاههای باتریدار مانند گوشیهای هوشمند، تبلتها و دستگاههای IoT ایدهآل میسازد. این کارایی انرژی همچنین به کاهش ردپای کربن و پایداری محیط زیست کمک میکند.
تخصصیسازی برای وظایف خاص
SLMها میتوانند برای وظایف خاص fine-tune شوند و در آن وظایف عملکرد بهتری نسبت به LLMهای عمومی داشته باشند. این تخصصیسازی منجر به دقت بالاتر و استفاده بهینه از منابع میشود.
استقلال از اتصال اینترنت
اجرای محلی به معنای عدم نیاز به اتصال دائمی به اینترنت است. این ویژگی برای مناطق با دسترسی محدود به اینترنت یا محیطهایی که اتصال پایدار وجود ندارد بسیار مفید است.
محبوبترین مدلهای زبانی کوچک
Llama 3.2
Meta با انتشار Llama 3.2 نسخههای 1B و 3B، مدلهایی کوچک و کارآمد ارائه داده است. این مدلها برای اجرای on-device طراحی شدهاند و در وظایف مختلف NLP عملکرد خوبی دارند.
Gemma 3
مدلهای Gemma 3 توسط Google ارائه شدهاند و شامل نسخههای text-only و multimodal میشوند. این مدلها کارایی بالایی در پردازش متن، تصویر و صوت دارند و برای کاربردهای متنوع مناسب هستند.
Microsoft Phi-3.5
خانواده Phi-3 از Microsoft شامل مدلهای 3B و 14B است که پشتیبانی از context طولانی (128K tokens) را ارائه میدهند. این مدلها در وظایف منطقی و ریاضی عملکرد بسیار خوبی دارند و برای خلاصهسازی اسناد طولانی و پاسخگویی به سوالات پیچیده مناسب هستند.
Mistral NeMo
Mistral NeMo یک مدل 12B است که با همکاری Mistral AI و NVIDIA توسعه یافته است. این مدل تعادل خوبی بین اندازه و عملکرد ارائه میدهد و برای کاربردهای تجاری مناسب است.
Qwen 2.5
مدلهای Qwen 2.5 توسط Alibaba ارائه شدهاند و روی dataset بزرگی (18 تریلیون token) آموزش دیدهاند. این مدلها پشتیبانی چندزبانه قوی دارند و تا 128K tokens context را پشتیبانی میکنند.
DeepSeek-R1
DeepSeek یکی از مدلهای پیشرفته NLP است که نسخههای کوچک آن عملکرد قابل توجهی در وظایف پردازش زبان طبیعی دارند.
کاربردهای مدلهای زبانی کوچک
Edge Computing و IoT
یکی از مهمترین کاربردهای SLMها در محاسبات لبه (Edge Computing) و اینترنت اشیا (IoT) است. این مدلها میتوانند روی سنسورها، دوربینهای امنیتی، دستگاههای پوشیدنی و ابزارهای خانگی هوشمند اجرا شوند و تصمیمگیری محلی را امکانپذیر سازند.
دستگاههای موبایل
گوشیهای هوشمند و تبلتها میتوانند از SLMها برای دستیارهای صوتی، ترجمه فوری، تشخیص متن و سایر قابلیتهای هوش مصنوعی استفاده کنند. این امر تجربه کاربری بهتری ایجاد میکند و به حریم خصوصی کمک میکند.
خودروهای خودران
در صنعت خودرو، SLMها برای تصمیمگیری سریع و محلی در سیستمهای ADAS و خودروهای خودران استفاده میشوند. تأخیر کم و پردازش محلی در این کاربردها بسیار حیاتی است.
سیستمهای امنیتی
تشخیص چهره، رفتارهای مشکوک و تجزیه و تحلیل real-time ویدیو در سیستمهای امنیت سایبری و فیزیکی از SLMها بهره میبرند.
مراکز بهداشتی و درمانی
در بخش سلامت، SLMها برای تشخیص بیماریها، تجزیه و تحلیل تصاویر پزشکی و ارائه توصیههای درمانی استفاده میشوند. حریم خصوصی بیمار در این حوزه بسیار مهم است و SLMها با پردازش محلی این نیاز را برطرف میکنند.
کسبوکارهای کوچک و متوسط
کسبوکارهای کوچک که بودجه محدودی دارند، میتوانند از SLMها برای خدمات مشتریان، بازاریابی دیجیتال، تولید محتوا و تحلیل داده استفاده کنند.
آموزش
در صنعت آموزش، SLMها برای دستیارهای آموزشی، ارزیابی خودکار، ترجمه محتوا و شخصیسازی تجربه یادگیری مورد استفاده قرار میگیرند.
کشاورزی هوشمند
در کشاورزی هوشمند، SLMها برای تحلیل سلامت گیاهان، پیشبینی محصول و مدیریت منابع آب استفاده میشوند.
SLM و سیستمهای Agentic AI
تحقیقات اخیر نشان میدهند که SLMها برای سیستمهای Agentic AI بسیار مناسب هستند. سیستمهای Agentic AI شامل چندین عامل (agent) هستند که با یکدیگر همکاری میکنند تا وظایف پیچیده را انجام دهند. در این سیستمها، استفاده از LLMها برای همه اجزا بسیار پرهزینه است.
SLMها میتوانند برای وظایف خاص مانند طبقهبندی، تصمیمگیری محلی و function calling استفاده شوند، در حالی که LLMها فقط برای وظایف پیچیدهتر که نیاز به استدلال عمیق دارند به کار گرفته شوند. این ترکیب باعث کاهش هزینه، افزایش سرعت و بهبود مقیاسپذیری میشود.
Federated Learning و SLM
یکی از روشهای نوین برای بهبود SLMها، استفاده از یادگیری فدرال (Federated Learning) است. در این روش، مدلهای کوچک روی دستگاههای مختلف آموزش میبینند و فقط بهروزرسانیهای مدل (نه دادههای خام) به سرور مرکزی ارسال میشود.
این رویکرد حریم خصوصی را حفظ میکند، پهنای باند شبکه را کاهش میدهد و از دادههای محلی هر دستگاه برای بهبود مدل استفاده میکند. ترکیب Federated Learning با SLMها یک راهحل قدرتمند برای سازمانهایی است که میخواهند از دادههای پراکنده خود بدون به خطر انداختن حریم خصوصی بهرهبرداری کنند.
چالشهای مدلهای زبانی کوچک
محدودیتهای دانش
SLMها به دلیل اندازه کوچکتر، دانش و اطلاعات کمتری نسبت به LLMها دارند. آنها ممکن است در وظایف پیچیده یا سوالات چندحوزهای عملکرد ضعیفتری داشته باشند.
نیاز به تخصصیسازی
برای عملکرد بهینه، SLMها معمولاً نیاز به fine-tuning برای وظایف خاص دارند. این فرآیند نیازمند داده، زمان و تخصص است.
هالوسیناسیون
هالوسیناسیون در مدلهای زبانی همچنان یک چالش است. SLMها ممکن است اطلاعات نادرست یا بیمعنی تولید کنند، که باید با روشهای مختلفی کنترل شود.
محدودیت context
بسیاری از SLMها پشتیبانی از context طولانی را ندارند، که این امر استفاده از آنها را در برخی کاربردها محدود میکند.
نیاز به بهینهسازی سختافزاری
برای اجرای کارآمد SLMها روی دستگاههای Edge، نیاز به بهینهسازیهای سختافزاری خاص است. این امر شامل استفاده از شتابدهندههای AI مانند NPU، TPU یا GPUهای تخصصی است.
آینده مدلهای زبانی کوچک
آینده SLMها بسیار روشن است. با پیشرفت تکنیکهای فشردهسازی، معماریهای کارآمدتر و سختافزارهای بهینهشده، انتظار میرود این مدلها عملکرد بهتری داشته باشند و در بیشتر دستگاهها یکپارچه شوند.
یکپارچگی با Multimodal AI
مدلهای چندوجهی (Multimodal) که میتوانند متن، تصویر، صوت و ویدیو را پردازش کنند، به تدریج در نسخههای کوچکتر در دسترس قرار میگیرند.
افزایش استفاده در شهرهای هوشمند
شهرهای هوشمند به طور فزایندهای از SLMها برای مدیریت ترافیک، انرژی، امنیت و خدمات عمومی استفاده خواهند کرد.
ترکیب با Quantum Computing
ترکیب SLMها با محاسبات کوانتومی میتواند عملکرد و کارایی را به سطوح جدیدی برساند.
استانداردسازی و ابزارهای بهتر
توسعه استانداردها و ابزارهای بهتر برای آموزش، استقرار و نگهداری SLMها، فرآیند پذیرش آنها را تسریع خواهد کرد.
توسعه معماریهای جدید
معماریهای نوین مانند Mamba و Mixture of Experts (MoE) به مدلهای کوچکتر کمک میکنند تا با منابع محدود، عملکرد بهتری داشته باشند.
افزایش دسترسی برای همه
با کاهش هزینهها و نیازهای سختافزاری، SLMها هوش مصنوعی را برای سازمانهای کوچک، کشورهای در حال توسعه و افراد عادی در دسترستر میکنند.
مقایسه SLM با LLM: کدام را انتخاب کنیم؟
انتخاب بین SLM و LLM به نیازهای خاص هر پروژه بستگی دارد:
SLM را انتخاب کنید اگر:
- نیاز به پردازش محلی و حریم خصوصی بالا دارید
- منابع محاسباتی و بودجه محدود دارید
- تأخیر کم برای شما بسیار مهم است
- میخواهید روی دستگاههای موبایل یا Edge اجرا کنید
- وظیفه شما تخصصی و محدود است
LLM را انتخاب کنید اگر:
- نیاز به دانش گسترده و استدلال پیچیده دارید
- وظایف شما متنوع و چندحوزهای است
- کیفیت خروجی مهمتر از هزینه است
- دسترسی به زیرساختهای ابری قوی دارید
- نیاز به context بسیار طولانی دارید
در بسیاری از موارد، ترکیب SLM و LLM بهترین راهحل است. استفاده از SLMها برای وظایف ساده و سریع و LLMها برای وظایف پیچیده، ترکیبی بهینه از عملکرد و هزینه ارائه میدهد.
ابزارها و فریمورکهای توسعه SLM
برای کار با SLMها، ابزارها و فریمورکهای مختلفی در دسترس هستند:
Ollama
Ollama یک ابزار محبوب برای اجرای مدلهای زبانی به صورت محلی است. این پلتفرم از مدلهای مختلفی مانند Llama، Mistral، Phi و Gemma پشتیبانی میکند و استفاده از آنها را بسیار ساده میکند.
TensorFlow Lite
TensorFlow Lite نسخه سبکوزن TensorFlow برای دستگاههای موبایل و Edge است که بهینهسازیهای خاصی برای اجرای کارآمد مدلها ارائه میدهد.
PyTorch Mobile
PyTorch Mobile اجرای مدلهای PyTorch را روی دستگاههای iOS و Android امکانپذیر میسازد.
ONNX Runtime
ONNX Runtime یک موتور استنتاج کراس-پلتفرم است که عملکرد بهینهای برای اجرای مدلهای مختلف ارائه میدهد و با سختافزارهای متنوعی سازگار است.
Hugging Face Transformers
کتابخانه Transformers از Hugging Face دسترسی آسان به صدها مدل از جمله SLMهای محبوب را فراهم میکند و ابزارهای قدرتمندی برای fine-tuning و استقرار ارائه میدهد.
LangChain
LangChain یک فریمورک محبوب برای توسعه اپلیکیشنهای مبتنی بر LLM و SLM است که ساخت عاملان هوش مصنوعی (AI Agents) را سادهتر میکند.
نکات کلیدی برای استفاده موثر از SLM
انتخاب مدل مناسب
قبل از انتخاب یک SLM، باید نیازهای خود را به دقت ارزیابی کنید:
- چه نوع وظیفهای باید انجام شود؟
- چه میزان دقت مورد نیاز است؟
- محدودیتهای سختافزاری چیست؟
- آیا نیاز به پشتیبانی چندزبانه دارید؟
- حجم دادههای آموزشی موجود چقدر است؟
Fine-tuning و Adaptation
برای بهترین عملکرد، SLMها باید برای وظیفه خاص شما fine-tune شوند. استفاده از تکنیکهای مدرن مانند LoRA (Low-Rank Adaptation) و QLoRA میتواند fine-tuning را با منابع محدود امکانپذیر سازد.
بهینهسازی و Quantization
پس از آموزش، بهینهسازی مدل برای اجرای کارآمد ضروری است. Quantization به 8-bit یا 4-bit میتواند حجم مدل را تا 75% کاهش دهد بدون افت قابل توجه در دقت.
مدیریت Context
با توجه به محدودیتهای context در SLMها، استفاده از تکنیکهایی مانند RAG (Retrieval-Augmented Generation) میتواند به مدل کمک کند تا به اطلاعات بیشتری دسترسی پیدا کند.
مانیتورینگ و ارزیابی
نظارت مستمر بر عملکرد مدل و شناسایی موارد هالوسیناسیون یا خطا بسیار مهم است. استفاده از متریکهای مناسب و تستهای منظم کیفیت خروجی را تضمین میکند.
تاثیر SLM بر دموکراتیزه شدن هوش مصنوعی
یکی از مهمترین تاثیرات SLMها، دموکراتیزه کردن دسترسی به هوش مصنوعی است. قبل از ظهور این مدلها، فقط شرکتهای بزرگ با بودجههای میلیونی میتوانستند از قدرت مدلهای زبانی بهرهمند شوند. اکنون:
- استارتاپها و کسبوکارهای کوچک میتوانند با بودجه محدود، راهحلهای هوش مصنوعی ایجاد کنند
- محققان و دانشگاهها میتوانند بدون نیاز به زیرساختهای گرانقیمت، تحقیقات پیشرفته انجام دهند
- کشورهای در حال توسعه میتوانند بدون وابستگی به سرویسهای ابری خارجی، فناوریهای هوش مصنوعی را توسعه دهند
- توسعهدهندگان فردی میتوانند اپلیکیشنهای نوآورانه ایجاد کنند
این دموکراتیزاسیون به نوآوری، رقابت و توسعه راهحلهای متناسب با نیازهای محلی کمک میکند.
SLM و پایداری محیط زیست
جنبه مهم دیگر SLMها، تاثیر مثبت آنها بر محیط زیست است. آموزش و اجرای LLMهای بزرگ مقادیر عظیمی انرژی مصرف میکند و ردپای کربن قابل توجهی دارد. SLMها با مصرف انرژی بسیار کمتر:
- کاهش انتشار کربن: مصرف انرژی کمتر به معنای انتشار گازهای گلخانهای کمتر است
- استفاده بهینه از منابع: نیاز به مراکز داده کمتر و سرورهای کوچکتر
- افزایش عمر دستگاهها: اجرای کارآمد روی سختافزارهای قدیمیتر، نیاز به ارتقا را کاهش میدهد
- کاهش پهنای باند: پردازش محلی به جای ارسال داده به سرورها
این ویژگیها SLMها را به گزینهای پایدارتر و مسئولانهتر برای سازمانهایی که به دنبال کاهش اثرات زیستمحیطی خود هستند تبدیل میکند.
مطالعات موردی و موفقیتهای واقعی
استفاده از SLM در پزشکی
بیمارستانهایی که از SLMها برای تحلیل تصاویر پزشکی استفاده میکنند، توانستهاند سرعت تشخیص را تا 60% افزایش دهند در حالی که حریم خصوصی بیماران را حفظ کردهاند.
خودروهای هوشمند
تولیدکنندگان خودرو از SLMها برای دستیارهای صوتی و سیستمهای ADAS استفاده میکنند که بدون اتصال به اینترنت کار میکنند و تأخیر زیر 50 میلیثانیه دارند.
کشاورزی دقیق
کشاورزان با استفاده از SLMهای نصب شده روی درونها و سنسورهای مزرعه، میتوانند سلامت گیاهان را تحلیل کنند و مصرف آب را تا 40% کاهش دهند.
خردهفروشی و تجارت
فروشگاههای خردهفروشی از SLMها برای تحلیل رفتار مشتریان، مدیریت موجودی و شخصیسازی پیشنهادات استفاده میکنند، که منجر به افزایش 25% در فروش شده است.
روندهای نوظهور در SLM
On-Device Training
یکی از روندهای جدید، امکان آموزش مدلها مستقیماً روی دستگاه است. این ویژگی به مدلها اجازه میدهد از رفتار و ترجیحات کاربر یاد بگیرند بدون ارسال دادهها به سرور.
Hybrid Models
ترکیب SLMها با LLMها به صورت هیبریدی، که در آن SLM وظایف ساده را به صورت محلی انجام میدهد و در صورت نیاز، کوئری به LLM در کلود ارسال میشود.
Specialized Accelerators
توسعه پردازندههای تخصصی برای AI مانند Apple Neural Engine، Google TPU و Qualcomm Hexagon که اجرای SLMها را بسیار کارآمدتر میکنند.
Cross-Platform Compatibility
ابزارها و استانداردهای جدیدی که اجرای یک SLM را روی پلتفرمهای مختلف (iOS، Android، Windows، Linux) بدون نیاز به تغییرات عمده امکانپذیر میسازند.
چگونه با SLM شروع کنیم؟
برای شروع کار با مدلهای زبانی کوچک، میتوانید این مراحل را دنبال کنید:
گام اول: شناسایی نیاز
وظیفه یا مشکلی که میخواهید حل کنید را مشخص کنید. آیا نیاز به پردازش متن، طبقهبندی، خلاصهسازی یا سوال-جواب دارید؟
گام دوم: انتخاب مدل
بر اساس نیازهای خود، یک SLM مناسب انتخاب کنید. مدلهای Phi-3.5، Llama 3.2 یا Gemma 2 برای شروع گزینههای عالی هستند.
گام سوم: آزمایش و ارزیابی
مدل را با دادههای خود تست کنید و عملکرد آن را ارزیابی کنید. اگر نیاز است، fine-tuning انجام دهید.
گام چهارم: بهینهسازی
مدل را برای استقرار بهینه کنید. Quantization، Pruning و سایر تکنیکها را اعمال کنید.
گام پنجم: استقرار
مدل را روی دستگاه یا سرور هدف مستقر کنید و نظارت بر عملکرد آن را آغاز کنید.
گام ششم: بهبود مستمر
بر اساس بازخورد کاربران و متریکهای عملکرد، مدل را بهطور مستمر بهبود دهید.
نتیجهگیری
مدلهای زبانی کوچک نشان دادهاند که هوش مصنوعی نیازی به مدلهای غولپیکر ندارد تا موثر باشد. با ترکیب کارایی، هزینه پایین، حریم خصوصی بالا و قابلیت اجرای محلی، SLMها در حال تغییر چشمانداز هوش مصنوعی هستند.
این مدلها نه تنها برای کسبوکارها و سازمانها بلکه برای جامعه نیز مزایای بسیاری دارند. دموکراتیزه شدن دسترسی به هوش مصنوعی، کاهش اثرات زیستمحیطی و امکان نوآوری گستردهتر، همگی از دستاوردهای SLMها هستند.
با پیشرفت مداوم در معماریها، تکنیکهای فشردهسازی و سختافزارهای تخصصی، آینده SLMها بسیار امیدوارکننده است. سازمانها و توسعهدهندگانی که هماکنون این فناوری را بپذیرند، در آینده از مزیت رقابتی قابل توجهی برخوردار خواهند بود.
توصیه نهایی: اگر به دنبال راهحلی هوشمند، مقرونبهصرفه و محافظ حریم خصوصی برای نیازهای هوش مصنوعی خود هستید، حتماً SLMها را بررسی کنید. آنها ممکن است دقیقاً همان چیزی باشند که پروژه شما به آن نیاز دارد.