وبلاگ / RAG در هوش مصنوعی: معرفی فناوری Retrieval-Augmented Generation و کاربردهای آن
RAG در هوش مصنوعی: معرفی فناوری Retrieval-Augmented Generation و کاربردهای آن
مقدمه
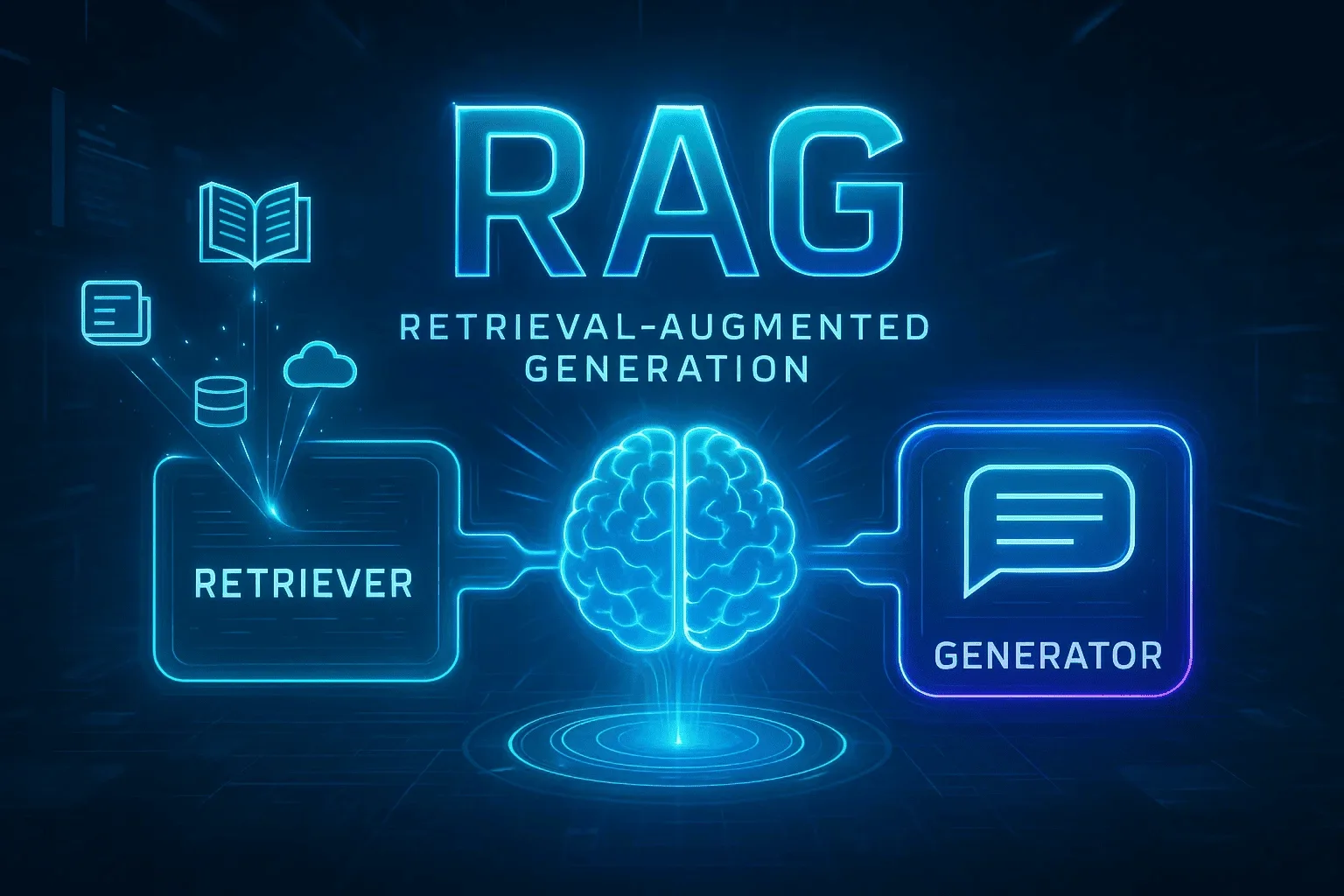
Retrieval-Augmented Generation یا RAG یکی از مهمترین پیشرفتهای حوزه هوش مصنوعی محسوب میشود که توانایی مدلهای زبانی بزرگ را به طرز چشمگیری افزایش داده است. این فناوری با ترکیب قابلیتهای بازیابی اطلاعات و تولید محتوا، راه حل نوآورانهای برای حل چالشهای موجود در سیستمهای AI ارائه میدهد.
در دنیای امروز که حجم عظیمی از دادهها تولید میشود، نیاز به سیستمهایی که بتوانند اطلاعات دقیق و بروز را در زمان واقعی بازیابی و پردازش کنند، بیش از پیش احساس میشود. RAG دقیقاً این نیاز را برآورده میسازد و به عنوان پلی میان دانش ایستا و اطلاعات پویا عمل میکند.
RAG چگونه کار میکند؟ درک عمیق معماری
Retrieval-Augmented Generation بر پایه ترکیب دو مرحله اساسی استوار است: بازیابی (Retrieval) و تولید (Generation). در مرحله اول، سیستم با استفاده از الگوریتمهای پیشرفته جستجو، مرتبطترین اطلاعات را از پایگاههای داده مختلف استخراج میکند. سپس در مرحله دوم، مدل زبانی بزرگ با استفاده از این اطلاعات بازیابیشده، پاسخی دقیق و متناسب با سوال کاربر تولید میکند.
معماری کلی سیستم RAG
فرآیند RAG از چهار مرحله اصلی تشکیل شده است:
1. نمایهسازی اطلاعات (Indexing)
در این مرحله، تمامی اسناد و منابع اطلاعاتی به بردارهای عددی (Embeddings) تبدیل شده و در پایگاه دادههای ویژهای ذخیره میشوند. این فرآیند امکان جستجوی سریع و دقیق را فراهم میآورد.
2. بازیابی (Retrieval)
هنگام دریافت پرسش کاربر، سیستم ابتدا سوال را تجزیه و تحلیل کرده و سپس با استفاده از معیارهای شباهت، مرتبطترین اطلاعات را از پایگاه داده استخراج میکند.
3. افزودن زمینه (Context Augmentation)
در این قدم، اطلاعات بازیابیشده به عنوان زمینه اضافی به پرسش اولیه کاربر اضافه میشود تا مدل زبانی دسترسی به اطلاعات جامعتری داشته باشد.
4. تولید پاسخ (Generation)
در نهایت، مدل زبانی بزرگ با استفاده از پرسش اصلی و اطلاعات بازیابیشده، پاسخی دقیق و کامل تولید میکند.
مزایای کلیدی فناوری RAG
1. دقت بالا و کاهش توهمزایی
یکی از مشکلات اصلی مدلهای زبانی سنتی، تولید اطلاعات نادرست یا خیالی موسوم به AI Hallucination است. RAG با ارائه منابع معتبر و قابل تأیید، این مشکل را به طور قابل توجهی کاهش میدهد. مطالعات نشان میدهند که این رویکرد 15% بهبود در دقت بازیابی برای تحلیل اسناد حقوقی داشته است.
2. بروزرسانی مداوم دانش
برخلاف مدلهای زبانی سنتی که دانش آنها در زمان آموزش ثابت میماند، RAG قابلیت دسترسی به اطلاعات بروز را فراهم میآورد. این ویژگی برای حوزههایی که نیاز به اطلاعات real-time دارند، بسیار ضروری است.
3. مقرون به صرفه بودن
بهروزرسانی مدلهای زبانی بزرگ فرآیندی پرهزینه و زمانبر محسوب میشود. RAG با امکان افزودن اطلاعات جدید بدون نیاز به آموزش مجدد مدل، راه حل اقتصادیتری ارائه میدهد.
انواع مختلف معماری RAG
1. RAG ساده (Naive RAG)
این نوع RAG شامل فرآیند خطی بازیابی و تولید است. در این روش، سیستم صرفاً بر اساس تشابه معنایی، مرتبطترین اسناد را بازیابی کرده و آنها را برای تولید پاسخ استفاده میکند.
2. RAG پیشرفته (Advanced RAG)
معماری پیشرفته RAG شامل تکنیکهایی مانند Re-ranking، Query Expansion و Multi-step Reasoning است که دقت و کیفیت نتایج را به طور قابل ملاحظهای بهبود میبخشد.
3. RAG چندمدال (Multimodal RAG)
نسل جدید RAG قابلیت پردازش انواع مختلف دادهها از جمله تصاویر، ویدئو و فایلهای صوتی را دارد. این تکنولوژی امکان تحلیل جامعتر اطلاعات را فراهم میآورد.
فناوریهای نوظهور در RAG
RAG دینامیک
RAG دینامیک توانایی تطبیق بازیابی در زمان تولید را دارد و به AI امکان پرسش سوالات تکمیلی در پاسخ به شکافهای نوظهور میدهد. این رویکرد شبیه به نحوه تصفیه جستجوهای انسانها در مکالمات واقعی عمل میکند.
نمایهسازی ترکیبی
استفاده از ترکیب بازنماییهای متراکم و پراکنده برای بهبود دقت بازیابی یکی دیگر از نوآوریهای مهم در این حوزه محسوب میشود. در حالی که embeddings متراکم در درنوردیدن مفاهیم معنایی عالی عمل میکنند، روشهای پراکنده در یافتن تطابقهای دقیق کلمات کلیدی مؤثرتر هستند.
دسترسی زمان واقعی به دادهها
پلتفرمهای RAG پیشرفته اکنون قابلیت اتصال مستقیم به منابع داده ساختاریافته از طریق API را دارند. این دسترسی real-time به GenAI امکان ترکیب بینشهای عملیاتی از دادههای ساختاریافته و غیرساختاریافته را میدهد.
کاربردهای عملی RAG در صنایع مختلف
1. حوزه پزشکی و سلامت
در صنعت بهداشت، RAG برای تحلیل پروندههای پزشکی و ارائه تشخیصهای دقیقتر استفاده میشود. سیستمهای RAG قادر به بررسی هزاران مقاله علمی و راهنمای بالینی در کسری از ثانیه هستند.
2. صنعت مالی
در حوزه مالی، RAG برای تحلیل مالی پیشرفته و مدلسازی ریسک استفاده میشود. این فناوری امکان ترکیب دادههای تاریخی، اخبار بازار و گزارشهای مالی را برای ارائه توصیههای سرمایهگذاری دقیقتر فراهم میآورد.
3. خدمات مشتری
RAG انقلابی در خدمات مشتری مبتنی بر یادگیری ماشین ایجاد کرده است. چتباتهایی که از این فناوری استفاده میکنند، قادر به ارائه پاسخهای دقیق و شخصیسازیشده بر اساس تاریخچه مشتری و دانش محصول هستند.
4. حوزه حقوقی
در صنعت حقوقی، RAG برای تحلیل قوانین، آرای قضایی و پروندههای مشابه استفاده میشود. این فناوری به وکلا کمک میکند تا در کسری از زمان، اطلاعات مرتبط با پروندههایشان را پیدا کنند.
پیادهسازی RAG: ابزارها و فریمورکها
فریمورکهای متن باز
LangChain و LlamaIndex از محبوبترین فریمورکهای پیادهسازی RAG محسوب میشوند. این ابزارها امکان ساخت سیستمهای RAG پیچیده را با کدنویسی کمتر فراهم میآورند.
پلتفرمهای ابری
خدمات ابری مانند Amazon Bedrock، Azure Cognitive Search و Google Vertex AI راهحلهای آماده و مقیاسپذیر برای پیادهسازی RAG ارائه میدهند.
پایگاههای داده برداری
Pinecone، Weaviate و Chroma از پرکاربردترین پایگاههای داده برداری برای ذخیرهسازی embeddings در سیستمهای RAG هستند.
چالشها و محدودیتهای RAG
کیفیت دادهها
یکی از مهمترین چالشهای RAG، وابستگی شدید آن به کیفیت دادههای ورودی است. اگر منابع اطلاعاتی نادرست یا قدیمی باشند، نتایج حاصل نیز متأثر خواهد شد.
پیچیدگی معماری
طراحی و پیادهسازی سیستمهای RAG پیچیده نیاز به تخصص عمیق در حوزههای مختلف از جمله یادگیری ماشین، مهندسی داده و معماری سیستم دارد.
مدیریت هزینه
اگرچه RAG در مقایسه با آموزش مجدد مدلها مقرونبهصرفهتر است، اما هزینههای زیرساختی مانند ذخیرهسازی embeddings و پردازش کوئریها میتواند قابل توجه باشد.
بهترین روشها برای پیادهسازی RAG
بهینهسازی کیفیت دادهها
قبل از پیادهسازی، باید اطمینان حاصل کرد که دادههای ورودی از کیفیت بالایی برخوردارند. این شامل پاکسازی، استانداردسازی و بروزرسانی منظم دادهها است.
انتخاب مدل embedding مناسب
انتخاب مدل embedding که بتواند مفاهیم مربوط به حوزه کاری شما را به خوبی درک کند، تأثیر زیادی در عملکرد نهایی سیستم دارد.
تنظیم پارامترهای بازیابی
پارامترهایی مانند تعداد اسناد بازیابیشده، آستانه شباهت و روشهای re-ranking باید بر اساس نیازهای خاص پروژه تنظیم شوند.
آینده RAG و تحولات پیش رو
تکامل به سمت Agent Systems
گفتمان پیرامون RAG کاهش یافته است چرا که توجه به سمت سیستمهای Agent جابجا شده. این تحول نشاندهنده انتقال از سیستمهای واکنشی به سیستمهای فعال و خودمختار است.
ادغام با فناوریهای نوظهور
ترکیب RAG با فناوریهایی مانند محاسبات کوانتومی و اینترنت اشیا آینده امیدوارکنندهای را برای این حوزه رقم خواهد زد.
RAG شخصیسازیشده
آینده RAG در جهت ارائه تجربههای کاملاً شخصیسازیشده بر اساس تاریخچه، ترجیحات و نیازهای هر کاربر حرکت خواهد کرد.
مطالعه موردی: پیادهسازی RAG در شرکت فناوری
یکی از شرکتهای بزرگ فناوری با پیادهسازی سیستم RAG برای پشتیبانی مشتریان، توانست زمان پاسخگویی را 70% کاهش دهد و رضایت مشتریان را 40% افزایش دهد. این سیستم شامل:
- پایگاه دانش محصولات شامل 50,000 سند
- مدل embedding سفارشی آموزشدیده روی دادههای خاص شرکت
- سیستم re-ranking پیشرفته برای بهبود دقت
تکنیکهای پیشرفته RAG
Graph RAG
Graph RAG از گرافهای دانش برای تقویت بازیابی از طریق درک روابط بین موجودیتها استفاده میکند. این رویکرد به ویژه برای پرسوجوهای پیچیده که نیاز به استدلال بر روی اطلاعات مترابط دارند، مؤثر است.
Contextual RAG
این تکنیک زمینه مکالمه را در طول تعاملات متعدد حفظ میکند و امکان پاسخهای منسجمتر و آگاه از زمینه را در مکالمات چند نوبتی فراهم میکند.
Federated RAG
Federated RAG امکان جستجو در چندین پایگاه دانش توزیع شده را با حفظ محدودیتهای حریم خصوصی و امنیت دادهها فراهم میکند.
بهینهسازی عملکرد RAG
بهینهسازی استراتژی تکهبندی
نحوه تقسیم اسناد به تکهها تأثیر قابل توجهی بر کیفیت بازیابی دارد. اندازههای بهینه تکه معمولاً بین ۲۰۰ تا ۸۰۰ توکن است، بسته به حوزه و مورد استفاده.
تنظیم دقیق جاسازی
تنظیم دقیق مدلهای جاسازی بر روی دادههای خاص حوزه میتواند دقت بازیابی را ۲۰ تا ۳۰ درصد نسبت به استفاده از جاسازیهای عمومی بهبود بخشد.
تکنیکهای تقویت بازیابی
تکنیکهای پیشرفته مانند جاسازی اسناد فرضی (HyDE) و بازیابی چند-پرسوجو میتوانند کیفیت زمینه بازیابی شده را به طور قابل توجهی بهبود بخشند.
ملاحظات امنیت و حریم خصوصی
حاکمیت داده
پیادهسازی سیستمهای RAG نیاز به در نظر گیری دقیق سیاستهای حاکمیت داده دارد، به ویژه هنگام کار با اطلاعات حساس یا محرمانه.
کنترل دسترسی
مکانیزمهای کنترل دسترسی دقیق تضمین میکنند که کاربران تنها اطلاعاتی را بازیابی کنند که مجاز به دسترسی به آن هستند.
ردیابی حسابرسی
نگهداری ردیابی جامع حسابرسی از تمام پرسوجوها و بازیابیها برای انطباق و نظارت امنیتی حیاتی است.
معیارهای ارزیابی برای سیستمهای RAG
معیارهای بازیابی
- دقت@K: نسبت اسناد مرتبط در K نتیجه برتر بازیابی شده را اندازهگیری میکند
- فراخوانی@K: نسبت اسناد مرتبط بازیابی شده از کل اسناد مرتبط را اندازهگیری میکند
- میانگین رتبه متقابل (MRR): کیفیت رتبهبندی را ارزیابی میکند
معیارهای تولید
- امتیاز BLEU: شباهت بین پاسخهای تولید شده و مرجع را اندازهگیری میکند
- امتیاز ROUGE: کیفیت خلاصههای تولید شده را ارزیابی میکند
- وفاداری: اندازهگیری میکند که آیا پاسخهای تولید شده با زمینه بازیابی شده سازگار هستند
کاربردهای خاص صنعت RAG
تجارت الکترونیک
RAG توصیههای شخصیسازی شده محصولات را با ترکیب دادههای رفتار کاربر با کاتالوگ محصولات و نظرات امکانپذیر میکند.
آموزش
پلتفرمهای آموزشی از RAG برای ارائه تجربیات تدریس شخصیسازی شده از طریق بازیابی مطالب یادگیری مرتبط بر اساس پیشرفت و پرسوجوهای دانشآموز استفاده میکنند.
تحقیق و توسعه
تیمهای R&D از RAG برای دسترسی سریع به ادبیات علمی مرتبط و پتنتها برای نوآوری و کشف استفاده میکنند.
چکلیست پیادهسازی RAG
فاز پیش از پیادهسازی
- تعریف موارد استفاده و معیارهای موفقیت
- ارزیابی کیفیت و در دسترس بودن دادهها
- انتخاب مدلهای جاسازی مناسب
- طراحی معماری سیستم
فاز پیادهسازی
- راهاندازی پایگاههای داده برداری
- پیادهسازی پایپلاینهای بازیابی و تولید
- پیکربندی مکانیزمهای رتبهبندی مجدد
- برقراری نظارت و ثبت وقایع
فاز پس از پیادهسازی
- نظارت بر عملکرد سیستم
- جمعآوری بازخورد کاربران
- تکرار روی استراتژیهای بازیابی
- بهروزرسانی منظم پایگاه دانش
نتیجهگیری
Retrieval-Augmented Generation فناوری انقلابی است که توانایی مدلهای زبانی را در ارائه پاسخهای دقیق و بروز به طرز چشمگیری افزایش داده است. این فناوری با ترکیب قدرت بازیابی اطلاعات و تولید محتوا، راه حل مؤثری برای چالشهای اساسی حوزه AI ارائه میدهد.
RAG در ادامه مسیر خود، سنگ بنای بازیابی و تولید اطلاعات باقی خواهد ماند و ترکیب قدرتمندی از روشهای بازیابی پیشرفته و مدلهای زبانی پیچیده ارائه خواهد داد.
برای سازمانهایی که به دنبال بهرهگیری از قدرت هوش مصنوعی برای بهبود خدمات و محصولات خود هستند، درک و پیادهسازی RAG گامی ضروری محسوب میشود. این فناوری نه تنها امروز بلکه در آینده نیز نقش کلیدی در شکلدهی به چشمانداز AI خواهد داشت.
با توجه به سرعت تحولات در این حوزه، پیگیری مستمر آخرین تکنیکها و ابزارها برای موفقیت در پیادهسازی RAG امری ضروری است. سرمایهگذاری در این فناوری امروز، مزیت رقابتی فردا را تضمین میکند.