وبلاگ / بهینهسازی و کارایی هوش مصنوعی: چگونه مدلهای AI را سریعتر و کمهزینهتر کنیم؟
بهینهسازی و کارایی هوش مصنوعی: چگونه مدلهای AI را سریعتر و کمهزینهتر کنیم؟

مقدمه
در عصری که هوش مصنوعی به سرعت در حال تبدیل شدن به ستون فقرات فناوریهای مدرن است، یک چالش بزرگ همچنان پابرجاست: هزینههای محاسباتی سنگین و مصرف انرژی بالا. مدلهای زبانی بزرگ مانند GPT-4 یا Claude 4 نیاز به منابع عظیمی برای آموزش و اجرا دارند. به عنوان مثال، آموزش یک مدل زبانی پیشرفته میتواند میلیونها دلار هزینه داشته باشد و انرژی معادل مصرف هزاران خانه را در یک سال مصرف کند.
اما چرا این موضوع اهمیت دارد؟ زیرا بدون بهینهسازی، AI قابل دسترسی نخواهد بود. شرکتهای کوچک نمیتوانند از این فناوری بهرهمند شوند، کاربران نهایی با تأخیرهای طولانی مواجه میشوند، و محیط زیست از انتشار کربن بیشتر آسیب میبیند. بهینهسازی و کارایی AI تنها یک مسئله فنی نیست؛ بلکه کلید دموکراتیک کردن هوش مصنوعی و پایدار نگه داشتن آن است.
در این مقاله، به بررسی عمیق روشها، تکنیکها و چالشهای بهینهسازی AI میپردازیم. از تکنیکهای کوانتیزاسیون گرفته تا معماریهای نوین مانند Mixture of Experts (MoE) و Small Language Models (SLM)، همه جنبهها را زیر ذرهبین میگذاریم.
چالشهای کارایی در مدلهای هوش مصنوعی
1. هزینههای محاسباتی و انرژی
یکی از بزرگترین چالشهای مدلهای بزرگ AI، نیاز به پردازندههای گرافیکی قدرتمند (GPU) و واحدهای پردازش تانسور (TPU) است. این سختافزارها نه تنها گران هستند، بلکه مصرف انرژی بسیار بالایی دارند. به عنوان مثال، اجرای یک جستجوی ساده با ChatGPT تقریباً ده برابر انرژی بیشتری نسبت به یک جستجوی گوگل مصرف میکند.
علاوه بر این، آموزش مدلهای بزرگ مانند GPT-5 یا Gemini 2.5 نیازمند مراکز داده عظیم با سیستمهای خنککننده پیشرفته است که خود هزینههای زیادی را به همراه دارد.
2. زمان تأخیر (Latency) و تجربه کاربری
در دنیای واقعی، کاربران انتظار پاسخهای فوری از سیستمهای AI دارند. اما مدلهای بزرگ معمولاً نیاز به زمان زیادی برای پردازش دارند، به خصوص زمانی که روی دستگاههای محلی اجرا میشوند. این تأخیر میتواند تجربه کاربری را به شدت کاهش دهد و کاربرد عملی AI را محدود کند.
3. محدودیتهای سختافزاری
بسیاری از کاربران و شرکتها دسترسی به سختافزارهای پیشرفته ندارند. دستگاههای موبایل، سیستمهای IoT و حتی لپتاپهای معمولی نمیتوانند مدلهای بزرگ را به راحتی اجرا کنند. این محدودیت، نیاز به بهینهسازی را دو چندان میکند.
4. مشکلات مقیاسپذیری
زمانی که تعداد کاربران یک سیستم AI افزایش مییابد، هزینههای اجرا به صورت خطی یا حتی نمایی رشد میکنند. بدون بهینهسازی مناسب، ارائه خدمات به میلیونها کاربر غیرممکن یا بسیار پرهزینه خواهد بود.
تکنیکهای پیشرفته بهینهسازی AI
کوانتیزاسیون (Quantization)
کوانتیزاسیون یکی از موثرترین روشهای کاهش حجم و افزایش سرعت مدلهای AI است. در این تکنیک، وزنهای مدل از نوع دادههای با دقت بالا (مانند float32) به انواع با دقت پایینتر (مانند int8 یا حتی int4) تبدیل میشوند.
مزایا:
- کاهش 75% حجم مدل با استفاده از کوانتیزاسیون 8-bit
- افزایش قابل توجه سرعت استنتاج (inference)
- کاهش مصرف حافظه و انرژی
انواع کوانتیزاسیون:
- Post-Training Quantization (PTQ): کوانتیزاسیون بعد از آموزش مدل
- Quantization-Aware Training (QAT): آموزش مدل با در نظر گرفتن کوانتیزاسیون از ابتدا
- Dynamic Quantization: کوانتیزاسیون پویا در زمان اجرا
برای پیادهسازی کوانتیزاسیون، میتوانید از فریمورکهایی مانند TensorFlow و PyTorch استفاده کنید که ابزارهای داخلی برای این منظور دارند.
Pruning (هرس کردن مدل)
Pruning فرآیند حذف نورونها یا اتصالات غیرضروری از یک شبکه عصبی است. تحقیقات نشان دادهاند که بسیاری از پارامترهای یک مدل عمیق تأثیر ناچیزی بر عملکرد نهایی دارند.
انواع Pruning:
- Unstructured Pruning: حذف وزنهای منفرد
- Structured Pruning: حذف کامل نورونها یا لایهها
- Magnitude-based Pruning: حذف وزنهایی که مقدار کوچکی دارند
با استفاده از Pruning میتوانید تا 90% از پارامترهای یک مدل را حذف کنید در حالی که دقت آن فقط چند درصد کاهش مییابد.
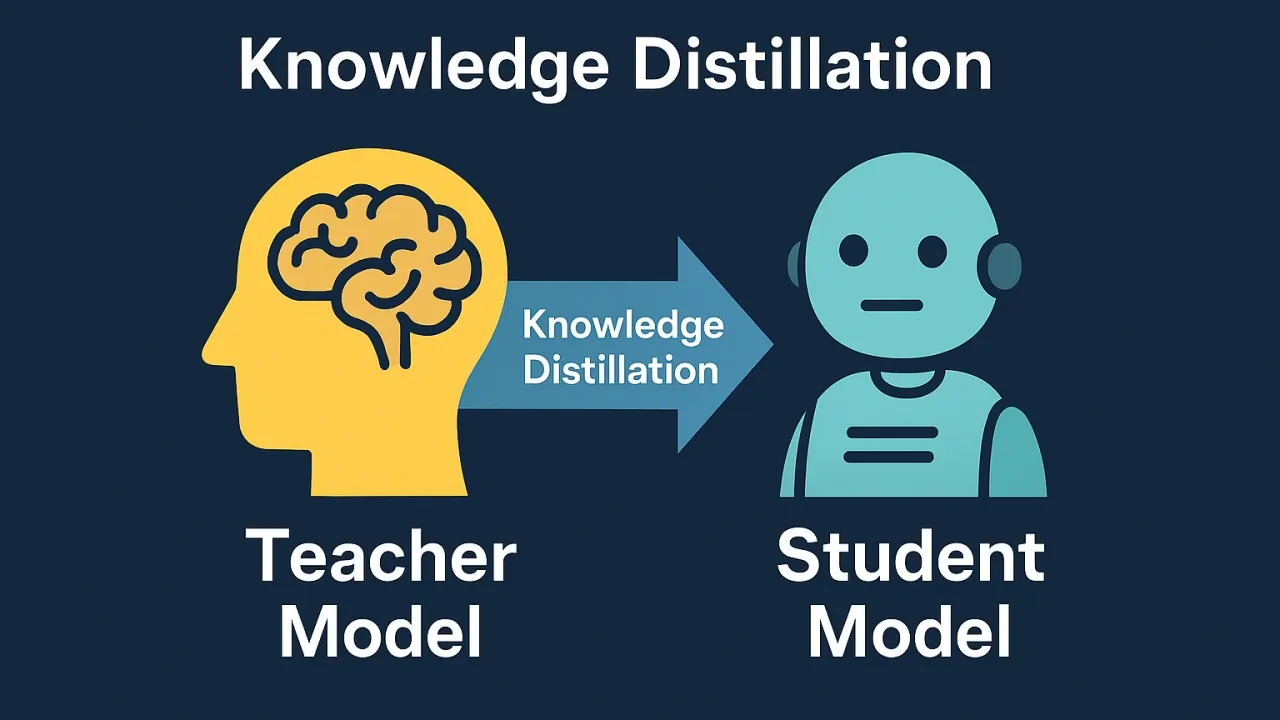
Knowledge Distillation (تقطیر دانش)
در این روش، یک مدل کوچکتر (Student) از یک مدل بزرگتر (Teacher) آموزش میبیند. مدل دانشآموز سعی میکند رفتار مدل معلم را تقلید کند، اما با تعداد پارامترهای بسیار کمتر.
این تکنیک برای ساخت Small Language Models بسیار کاربردی است و به شما امکان میدهد مدلهایی بسازید که روی دستگاههای محلی قابل اجرا باشند.
Low-Rank Adaptation (LoRA)
LoRA یک تکنیک انقلابی برای Fine-tuning مدلهای بزرگ است. به جای بهروزرسانی تمام وزنهای مدل، LoRA فقط ماتریسهای کوچکی را اضافه و آموزش میدهد که به شدت هزینههای محاسباتی را کاهش میدهد.
مزایای LoRA:
- کاهش 99% حافظه مورد نیاز برای Fine-tuning
- امکان آموزش روی GPU های معمولی
- حفظ کیفیت مدل اصلی
Edge AI و پردازش محلی
Edge AI به اجرای مدلهای هوش مصنوعی روی دستگاههای محلی اشاره دارد. این رویکرد مزایای زیادی دارد:
- حذف نیاز به ارتباط دائمی با سرور
- کاهش تأخیر به حداقل
- حفظ حریم خصوصی کاربران
- کاهش هزینههای زیرساخت ابری
برای پیادهسازی Edge AI، نیاز به بهینهسازی شدید مدلها دارید. استفاده از فریمورکهایی مانند TensorFlow Lite یا ONNX Runtime میتواند کمک کننده باشد.
معماریهای کارآمد برای AI
Mixture of Experts (MoE)
معماری MoE یک روش هوشمندانه برای افزایش ظرفیت مدل بدون افزایش متناسب هزینه محاسباتی است. در این معماری، تنها بخشی از مدل (معمولاً 10-20%) برای هر ورودی فعال میشود.
چگونگی کار:
- مدل شامل چندین "متخصص" (Expert) است
- یک شبکه Router تصمیم میگیرد کدام متخصصها برای هر ورودی فعال شوند
- هر متخصص روی یک حوزه خاص تخصص دارد
مدلهایی مانند DeepSeek V3.2 از این معماری استفاده میکنند و عملکرد فوقالعادهای با هزینه پایین ارائه میدهند.
Transformer بهینهشده و جایگزینها
مدل Transformer اگرچه قدرتمند است، اما دارای پیچیدگی محاسباتی O(n²) نسبت به طول توالی ورودی است. چند جایگزین کارآمدتر عبارتند از:
1. Mamba Architecture:
Mamba بر پایه State Space Models ساخته شده و پیچیدگی خطی O(n) دارد. این معماری برای توالیهای بلند بسیار کارآمدتر از Transformer است.
2. RWKV:
RWKV ترکیبی از RNN و Transformer است که مزایای هر دو را دارد: کارایی RNN در استنتاج و قدرت Transformer در موازیسازی آموزش.
3. Liquid Neural Networks:
شبکههای عصبی مایع میتوانند پارامترهای خود را به صورت پویا تنظیم کنند و برای محیطهای در حال تغییر بسیار مناسب هستند.
Small Language Models (SLM)
مدلهای زبانی کوچک نشان دادهاند که همیشه بزرگتر بهتر نیست. مدلهایی با کمتر از یک میلیارد پارامتر میتوانند برای وظایف خاص عملکرد فوقالعادهای داشته باشند.
مثالهای موفق SLM:
- Phi-3 Mini از مایکروسافت با 3.8 میلیارد پارامتر
- Gemma 2B از گوگل
- مدلهای متخصص در حوزههای خاص
این مدلها برای ساخت اپلیکیشن با AI روی دستگاههای محلی ایدهآل هستند.
بهینهسازی در سطح سختافزار
چیپهای اختصاصی AI
چیپهای سفارشی AI برای عملیات خاص هوش مصنوعی طراحی میشوند و کارایی بسیار بالاتری نسبت به CPU یا حتی GPU های عمومی دارند.
انواع چیپهای اختصاصی:
- TPU (Tensor Processing Unit): طراحی شده توسط گوگل برای عملیات ماتریسی
- NPU (Neural Processing Unit): موجود در گوشیهای هوشمند مدرن
- IPU (Intelligence Processing Unit): ساخته شده توسط Graphcore
- Apple Neural Engine: در چیپهای M و A سری
Neuromorphic Computing
محاسبات نوروморفیک تلاش میکنند ساختار مغز را تقلید کنند. این چیپها از پردازش event-driven استفاده میکنند و مصرف انرژی بسیار کمتری دارند.
چیپهای نوروموفیک مانند Intel Loihi 2 میتوانند وظایف AI را با کسری از انرژی مورد نیاز GPU های سنتی انجام دهند.
Quantum AI
هوش مصنوعی کوانتومی هنوز در مراحل اولیه است، اما پتانسیل تغییر کامل قواعد بازی را دارد. کامپیوترهای کوانتومی میتوانند مسائل بهینهسازی خاصی را به طور تصاعدی سریعتر از کامپیوترهای کلاسیک حل کنند.
تکنیکهای بهینهسازی نرمافزاری
Efficient Attention Mechanisms
مکانیزم Attention در Transformer ها گلوگاه اصلی عملکرد است. چند نسخه بهینهشده وجود دارد:
1. Flash Attention:
استفاده بهینه از حافظه GPU برای کاهش زمان محاسبه Attention
2. Multi-Query Attention (MQA):
استفاده مجدد از Key و Value برای کاهش حافظه
3. Grouped-Query Attention (GQA):
حد وسطی بین MQA و Multi-Head Attention استاندارد
4. Sparse Attention:
محاسبه Attention فقط برای بخشی از توکنها، همانطور که در DeepSeek V3.2 استفاده شده است
Caching و Optimization در Inference
KV Caching:
ذخیرهسازی Key-Value های محاسبه شده برای توکنهای قبلی تا از محاسبه مجدد جلوگیری شود. این تکنیک میتواند سرعت تولید متن را 2-3 برابر افزایش دهد.
Speculative Decoding:
استفاده از یک مدل کوچک برای پیشبینی توکنهای بعدی و سپس تأیید آنها با مدل بزرگ
Batching:
پردازش چند درخواست به صورت همزمان برای استفاده بهینه از GPU
راهکارهای حافظه و ذخیرهسازی
Gradient Checkpointing:
ذخیره فقط بخشی از فعالسازیها در حین آموزش و محاسبه مجدد بقیه در صورت نیاز
Mixed Precision Training:
استفاده از float16 یا bfloat16 به جای float32 در بیشتر محاسبات
Activation Checkpointing:
کاهش استفاده از حافظه با مبادله بین زمان و حافظه
Retrieval-Augmented Generation (RAG) برای کارایی
RAG به مدلهای زبانی اجازه میدهد به جای ذخیره تمام دانش در پارامترها، از یک پایگاه دانش خارجی استفاده کنند. این رویکرد مزایای زیادی دارد:
- کاهش نیاز به پارامترهای زیاد
- امکان بهروزرسانی دانش بدون آموزش مجدد
- کاهش Hallucination
- افزایش قابلیت اطمینان پاسخها
RAG به خصوص برای کاربردهایی که نیاز به دانش خاص حوزه دارند (مانند پزشکی یا حقوقی) بسیار مناسب است.
Federated Learning برای حریم خصوصی و کارایی
یادگیری فدرال امکان آموزش مدلهای AI روی دادههای توزیع شده بدون جابجایی دادهها را فراهم میکند. این رویکرد:
- حریم خصوصی را حفظ میکند
- هزینههای انتقال داده را کاهش میدهد
- امکان استفاده از دادههای حساس را فراهم میکند
- برای یادگیری از دستگاههای لبه ایدهآل است
استراتژیهای بهینهسازی برای کاربردهای خاص
بهینهسازی برای تولید تصویر و ویدیو
مدلهای تولید تصویر و ویدیو نیازمند منابع محاسباتی فوقالعادهای هستند. راهکارهای بهینهسازی شامل:
1. Latent Diffusion Models:
انجام Diffusion در فضای latent به جای فضای پیکسلی
2. Few-Step Generation:
کاهش تعداد مراحل diffusion از 50-100 به 4-8 مرحله
3. Model Distillation:
استفاده از مدلهای کوچکتر آموزش دیده از مدلهای بزرگ
بهینهسازی برای پردازش زبان طبیعی
NLP یکی از حوزههای پرهزینه AI است. تکنیکهای بهینهسازی:
- استفاده از Tokenization کارآمد
- Fine-tuning با LoRA به جای Full Fine-tuning
- استفاده از Prompt Engineering برای بهبود نتایج بدون آموزش
بهینهسازی برای سیستمهای Real-Time
کاربردهایی مانند خودروهای خودران و رباتیک نیاز به پاسخ در زمان واقعی دارند:
- استفاده از مدلهای کوچک و تخصصی
- پیادهسازی روی Edge با سختافزار اختصاصی
- استفاده از مدلهای سلسلهمراتبی (ابتدا مدل سریع، سپس در صورت نیاز مدل دقیقتر)
چالشهای آینده و راهکارها
Self-Improving AI Models
مدلهای خودبهبود میتوانند خودشان را بهینه کنند. این رویکرد آیندهدار است اما چالشهایی دارد:
- خطر بهینهسازی بیش از حد برای معیارهای اشتباه
- نیاز به نظارت دقیق برای جلوگیری از رفتارهای ناخواسته
- موازنه بین بهبود و ثبات
Multi-Agent Systems و بهینهسازی توزیع شده
سیستمهای چندعامله میتوانند وظایف پیچیده را به زیروظایف تقسیم کنند و هر عامل روی بخش خاصی تمرکز کند. این رویکرد امکان بهینهسازی محلی و کارایی بهتر را فراهم میکند.
World Models و یادگیری کارآمد
World Models به AI اجازه میدهند شبیهسازیهای ذهنی از دنیا داشته باشند. این امر میتواند نیاز به دادههای آموزشی واقعی را کاهش دهد و یادگیری را کارآمدتر کند.
ابزارها و فریمورکهای عملی
فریمورکهای بهینهسازی
1. ONNX Runtime:
اجرای بهینهشده مدلهای یادگیری ماشین روی سختافزارهای مختلف
2. TensorRT:
کتابخانه بهینهسازی NVIDIA برای استنتاج سریع
3. OpenVINO:
ابزار Intel برای بهینهسازی و استقرار مدلها
4. Hugging Face Optimum:
ابزارهای بهینهسازی برای مدلهای Transformer
پلتفرمهای Cloud AI بهینه
Google Cloud AI و سایر ارائهدهندگان ابری خدمات بهینهسازی خودکار ارائه میدهند:
- Auto-scaling برای مدیریت بار
- Model optimization APIs
- سختافزارهای اختصاصی (TPU، GPU)
معیارهای سنجش کارایی
برای ارزیابی بهینهسازی، باید معیارهای مختلفی را در نظر بگیرید:
1. Throughput:
تعداد درخواستهای پردازش شده در واحد زمان
2. Latency:
زمان پاسخ برای یک درخواست منفرد
3. Memory Usage:
حافظه RAM و VRAM مصرفی
4. Energy Consumption:
مصرف انرژی برای هر استنتاج
5. Model Size:
حجم مدل روی دیسک
6. Accuracy:
دقت مدل نسبت به نسخه بهینهنشده
مطالعات موردی و موفقیتها
DeepSeek: بهینهسازی با هزینه کم
DeepSeek نشان داد که میتوان با بودجه محدود، مدلهایی در سطح GPT-4 ساخت. استراتژیهای آنها شامل:
- استفاده از معماری MoE
- بهینهسازی شدید کد آموزش
- استفاده از سختافزار کمهزینهتر با مدیریت هوشمندانه
Claude و کارایی بالا
Claude و نسخههای جدید آن مانند Claude Sonnet 4.5 نشان دادهاند که میتوان هم هوشمند و هم کارآمد بود. استفاده از تکنیکهای بهینهسازی پیشرفته باعث شده این مدلها سرعت پاسخدهی فوقالعادهای داشته باشند.
O3 Mini و O4 Mini: کارایی در مقیاس کوچک
O3 Mini و O4 Mini از OpenAI نمونههای عالی از مدلهای بهینهشده هستند که با منابع کمتر، عملکرد قابل قبولی ارائه میدهند.
استراتژیهای کاهش هزینه در تولید
استفاده از Model Cascading
به جای استفاده از یک مدل بزرگ برای همه درخواستها، میتوانید از یک سیستم سلسلهمراتبی استفاده کنید:
- درخواست ابتدا به مدل کوچک و سریع میرود
- اگر اعتماد پایین بود، به مدل متوسط منتقل میشود
- فقط درخواستهای پیچیده به مدل بزرگ میروند
این رویکرد میتواند هزینهها را تا 70% کاهش دهد.
Prompt Caching
ذخیرهسازی قسمتهای تکراری پرامپتها میتواند هزینهها را به طور قابل توجهی کاهش دهد. این تکنیک به خصوص برای چت با AI که دارای context طولانی است مفید است.
Batch Processing
پردازش دستهای درخواستها به جای پردازش تکتک آنها میتواند کارایی را تا 10 برابر افزایش دهد. این رویکرد برای کاربردهایی که نیاز به پاسخ فوری ندارند ایدهآل است.
بهینهسازی برای کاربردهای تخصصی
AI در پزشکی و تشخیص بیماری
AI در تشخیص و درمان نیاز به دقت بالا دارد، اما همچنین باید سریع باشد. راهکارها:
- استفاده از مدلهای تخصصی آموزش دیده روی دادههای پزشکی
- بهینهسازی برای سختافزارهای موجود در بیمارستانها
- استفاده از Edge AI برای حفظ حریم خصوصی بیماران
AI در امنیت سایبری
هوش مصنوعی در امنیت سایبری نیاز به پردازش real-time دارد:
- مدلهای سبک برای تشخیص anomaly
- استفاده از Isolation Forest برای کشف ناهنجاریها
- معماریهای توزیع شده برای مقیاسپذیری
AI در مالی و معاملات
AI در معاملات نیاز به latency بسیار پایین دارد:
- استفاده از مدلهای سادهتر برای تصمیمگیری سریع
- پیشپردازش دادهها برای کاهش بار در زمان واقعی
- استفاده از مدلهای پیشبینی بهینهشده
ملاحظات اخلاقی و محیطی
کاهش ردپای کربن
بهینهسازی AI تنها یک مسئله اقتصادی نیست، بلکه یک مسئله اخلاقی و زیستمحیطی است. اخلاق در هوش مصنوعی ایجاب میکند که:
- از انرژیهای تجدیدپذیر برای آموزش استفاده کنیم
- مدلها را فقط زمانی آموزش دهیم که واقعاً نیاز است
- از مدلهای پیشآموزش شده استفاده مجدد کنیم
دسترسی عادلانه به AI
بهینهسازی باعث میشود AI برای همه در دسترس باشد، نه فقط شرکتهای بزرگ. این امر برای آینده هوش مصنوعی و دموکراتیک شدن آن حیاتی است.
راهنمای عملی برای شروع بهینهسازی
گام 1: پروفایل کردن مدل
ابتدا باید بفهمید کجاهای مدل شما گلوگاه دارد:
- استفاده از ابزارهای profiling مانند PyTorch Profiler
- شناسایی لایههایی که زمان بیشتری میگیرند
- بررسی استفاده از حافظه
گام 2: انتخاب تکنیک مناسب
بسته به نیاز خود، یکی یا ترکیبی از تکنیکهای زیر را انتخاب کنید:
- برای کاهش حجم: Quantization و Pruning
- برای کاهش latency: Knowledge Distillation و Model Caching
- برای کاهش هزینه آموزش: LoRA و Federated Learning
گام 3: پیادهسازی و تست
- شروع با یک تکنیک و ارزیابی نتایج
- مقایسه معیارهای کلیدی (دقت، سرعت، حافظه)
- Fine-tuning پارامترها برای بهینهسازی بیشتر
گام 4: مانیتورینگ و بهبود مستمر
- استفاده از ابزارهای مانیتورینگ برای ردیابی عملکرد
- A/B testing برای مقایسه نسخههای مختلف
- بهروزرسانی منظم با تکنیکهای جدید
ابزارهای توسعه و کتابخانهها
TensorFlow و PyTorch
TensorFlow و PyTorch هر دو ابزارهای جامعی برای بهینهسازی دارند:
TensorFlow:
- TensorFlow Lite برای موبایل
- TensorFlow.js برای مرورگر
- TensorFlow Serving برای production
PyTorch:
- TorchScript برای optimization
- PyTorch Mobile
- TorchServe برای deployment
کتابخانههای تخصصی
آینده بهینهسازی AI
AI Agent ها و بهینهسازی خودکار
AI Agent ها میتوانند خودشان تصمیم بگیرند چه زمانی و چگونه بهینهسازی کنند. Agentic AI آینده بهینهسازی است.
AGI و کارایی نهایی
مسیر به سمت AGI نیازمند پیشرفتهای اساسی در کارایی است. ما نمیتوانیم AGI بسازیم مگر اینکه بتوانیم آن را با منابع معقول اجرا کنیم.
Physical AI و رباتیک
Physical AI نیاز به بهینهسازی شدیدتری دارد زیرا باید روی ربااتها با منابع محدود اجرا شود.
نتیجهگیری
بهینهسازی و کارایی AI نه یک انتخاب، بلکه یک ضرورت است. در دنیایی که AI به سرعت در حال گسترش است، تنها سازمانها و توسعهدهندگانی موفق خواهند بود که بتوانند مدلهای خود را کارآمد، سریع و مقرون به صرفه کنند.
از کوانتیزاسیون ساده گرفته تا معماریهای پیشرفته مانند MoE، ابزارها و تکنیکهای فراوانی در اختیار ما هستند. کلید موفقیت در درک عمیق نیازهای خاص پروژه و انتخاب ترکیب مناسبی از این تکنیکها است.
به یاد داشته باشید که بهینهسازی یک فرآیند مستمر است. با پیشرفت سریع فناوری، روشهای جدیدی به طور مداوم معرفی میشوند. تنها با یادگیری مداوم و آزمایش تکنیکهای جدید میتوانید در این حوزه پیشرو بمانید.
آینده AI متعلق به کسانی است که میتوانند قدرت و کارایی را با هم ترکیب کنند. با استفاده از راهکارهای ارائه شده در این مقاله، شما هم میتوانید بخشی از این آینده باشید و مدلهای AI خود را به سطح جدیدی از عملکرد برسانید.